
Backup &Recovery Scenarios
by Muhammad Abdul Halim
To check database mode
> archive log list
To bring database in archive log mode
> startup mount
> alter database archivelog;
To start ARCN process
log_archive_start=true
log_archive-max_process=2(max 10)
> ALTER SYSTEM SET LOG_ARCHIVE_MAX_PROCESSES=3;
> ALTER SYSTEM ARCHIVE LOG START STOP
To define archive format
log_archive_format=TS%S.ARC
Data Dictionary Format
V$ARCHIVED_LOG V$ARCHIVE_DEST
V$LOG_HISTORY V$ARCHIVE_PROCESSES
To define archive destination : Up to 4 destination can be defined
log_archive_dest=’/clover/archive’
log_archive_duplex_dest=’/clover/archive’
OR
log_archive_dest_1=”LOCATION=/clover/arch”
Mandatory Reopen=500(Default 300) Optional
log_archive_min_succeed_dest=2
log_archive_dest_state_3=DEFER / ENABLE
> ALTER SYSTEM SET log_archive_dest_state_3=ENABLE;
log_archive_dest_state_2=”SERVICE=standby”
To defining archive destination in open database
> ALTER SYSTEM ARCHIVE LOG START TO ’/clover/arch’;
Selectively Archiving
> ALTER SYSTEM ARCHIVE LOG SEQUENCE 052;
BACKUP AND RECOVERY
Media Failure and Recovery:
Database in NOARCHIVELOG Mode
Failure : loss of disk,data file,or corruption
Recovery : Restore all Oracle files:
- Data files
- Control files
- Redo log files
- Password file (optional)
- Parameter file (optional)
Advantage
· Easy to perform with low risk of error
· Recovery time is the time it takes to restore all files.
Disadvantage
· Data is lost and must be reapplied manually
· The entire database is restored to the point of the last whole closed backup
Recovery
> shutdown
Restore all files using operating system
> startup
Restoring to a Different Location
> startup mount
> alter database rename file ’/clover/oradata/user_01.dbf’ to ’/clover/oradata/user_01.dbf’;
> alter database open;
Media Failure and Recovery:
ARCHIVELOG Mode
Failure : loss of disk,data file,or corruption
Recovery
- Data files for restore must be offline.
- Restore only lost or damaged data files
- Do not restore the control files, redo log files, password files, or parameter files
- Recover the data files.
Advantages
· Only need to restore lost files
· Recovers all data to the time of failure
· Recovery time is the time it takes to restore lost files and apply all archived log files
Disadvantages
· Must have all archived log files since the backup from which you are restoring
Complete recovery
· Closed database recovery for
- System data files
- Rollback segment data files
- Whole database
· Opened database recovery, with database initially opened : for file loss
· Opened database recovery with database initially closed : for hardware failure
· Data file recovery with no data file backup
Incomplete recovery
· Time based
· Cancel based
· Using control file
· Change based
Closed database backup
No archive log mode
Data files, Control files, Redolog files, Parameter file, Password file
> SHUTDOWN IMMEDIATE
cp /backup
> STARTUP OPEN;
Open database backup
Archive log mode
Data files, Control files, Parameter file, Password file
Arch process must be enabled
> alter tablespace TEST begin backup;
cp /clover/data/test.dbf /clover/backup/test.dbf
> alter tablespace TEST end backup;
Creating a binary image;
> alter database backup controlfile to ‘controll.bk
Creating a text trace file:
> alter database backup controlfile to trace;
Case Study for Backup and recovery
Backups
I. Closed database backup
Note : To keep backup, create one subfolder in your main folder Every day before shutdown delete all your backups.
Database may in no archive/archive log mode
Take backup of all files Data files, Control files, Redolog files,
Parameter file, Password file (optional )
> SHUTDOWN IMMEDIATE;
Copy all files to backup location using operating system.
cp /clover/backup/
> STARTUP OPEN;
II Open database backup
Database must be in archive log made
ARCN process must be enabled
Take backup of Data files, Control files
Password file and Parameter file is optional
> alter tablespace test begin backup;
Copy datafile of test tablespace to backup location using operating system.
cp /oracle/db01/data/test.dbf /oracle/backup/test.dbf
> alter tablespace test end backup;
Note : Perform open database backup for all tablespaces
Creating a binary image of control file
> alter database backup controlfile to ‘controll.bkp; path should be specified
Creating a text trace file
> alter database backup controlfile to trace; path should be specified
Recovery
Recovery in No Archive log mode :
Advantage : Easy to perform with minimum risk
Recovery time is time taken for restore the files from backup
Disadvantage : Data lost must be reapplied manually
Database is recovered to time of last backup.
Possible media failure : Loss of disk, datafile or corruption of datafile.
Requirement : Last valid closed database backup.
Recovery : Restore all datafiles, control files, redolog files.
Recover the database.
Note : if log sequence no is not changed after taking the backup no need restore all file.
Scenario 1
Shutdown the database.
> shutdown
copy all datafiles, control files, redolog files to backup folder using operating system.
Delete one datafile using operating system.
> startup ( Database will go to mount stage giving an error )
Recovery
Restore damaged datafile from backup using operating system and recover
cp /oracle/backup /oracle/db01/data
> alter database open ;
Scenerio 2
Force the log switch to change the log seq no.
> alter system switch logfile;
> alter system switch logfile;
> alter system switch logfile;
Shutdown the database.
> shutdown
Delete one datafile using operating system.
> startup ( Database will go to mount stage giving an error )
Recovery
Restore all files.
> alter database open ;
Recovery in Archive log mode : ( Complete Recovery )
Advantage : Restore damaged datafile
Recover all data to the time od failure
Recovery time is time taken to restore datafile and apllying the archive logs.
Disadvantage : Require all archive logs since the backup from which are restored
Possible media failure : Loss of disk , datafile or corruption of datafile.
Requirement : Last valid backup after seting database in archive log mode.
All archive logs and online redologs which are not yet archived
Recovery : Startup the database in mount/open stage
Restore damaged datafile from backup using operating system recover
Recover the datafile.
Recovery syntax
Recovering in mount stage
> Recover database
> Recover datafile ’’;
> Alter database recover database;
Manual recovery
If archive log destination is not defined in the parameter file
Oracle server has to be informed about the location of the file archive logs.
> Alter system archive log start to ;
To recover also you have to define the archive log location
> recover from <> database;
Automatic recovery
Before recover set auto recovery on.
> set auto recovery on;
> recover datafile ‘’;
Enter auto when prompted for a redolog file.
> Auto
Or
> recover automatic datafile ‘’
Check V$recover_file - which file need recovery
V$recovery_log - archive log need for recovery
Recovery in Archive log mode : ( Complete Recovery )
Scenario 3 ( In mount stage )
Force the log switch to change the log seq no.
> alter system switch logfile ;
> alter system switch logfile;
> alter system switch logfile ;
shutdown the database.
> shutdown immediate ;
Delete system datafile using operating system.
> startup ( Database will go to mount stage giving an error )
ORA-01157 : cannot identify/lock data file 1 – see DBWR trace file
ORA-01110 : data file 1 : ‘/clover/system01.dbf'
Restore system datafile from backup using oprating system and recover the datafile
> Recover datafile ‘/clover/data/sys.dbf’ ;
> Alter database open ;
Scenario 4 ( Initially closed, open stage )
Shutdown the database.
> shutdown immediate ;
Delete non system datafile using operating systm.
> startup ( Database will go to mount stage giving an error )
ORA-01157 : cannot Identify/lock data file 3 – see DBWR trade file
ORA-01110 : data file 3 : ‘/clover/test.dbf’
Check V$ datafile header
Take the lost datafile offline
> Alter database datafile ‘/clover/test.dbf’ offline;
Restore the lost datafile from backup and recover the datafile.
> Recover datafile /clover/test.dbf ;
Bring the datafile online.
> Alter database datafile ‘/clover/test.dbf’ online;
Note : if you want to restore the damaged datafile to different location oracle must
Be informed about new location by renaming recovery
> Alter database rename file ‘/clover/test.dbf’ to ‘/new/test.dbf’ ;
Backup Recovery
Recovery in Archive log mode : ( Complete Recovery )
Scenario 5 ( without backup )
Shutdown the database.
> shutdown immediate ;
Delete non system datafile using operating system.
> startup ( Database will go to mount stage giving an error )
ORA-01157 : cannot identify/lock data file 3 – see DBWR trace file
ORA-01110 : data file 3 : ‘/clover/test.dbf’
Take the lost datafile oflinne
> Alter database datafile ‘/clover/test.dbf’ ofline;
open the database
> Alter database open ;
Take database offile immediate to avoid check point trying to write to datafile.
> Alter tablespace test offline immediate ;
Since you do not have backup operate create the datafile
> Alter database create datafile ‘/clover/test.dbf’ as ‘/clover/test.dbf’;
Recover the Database
> Recover datafile ‘/clover/test.dbf’;
> Alter tablespace test online ;
Scenerio 6 Recovery of file in backup mode
Startup online backup
> Alter tablespace test begin backup ;
switch off the system and restart .
startup the database if it is already starting shut it down then startup. It will ask for media recovery
ORA-01113 : file 3 needs media recovery
ORA-01110 : data file 3 : ‘/clover/test.dbf’
Check V$Backup
> Recover datafile '/clover/test.dbf’;
OR
> Alter database datafile 3 end backup ;
check V$Backup
Since the datafile header was frozen the database files were not synchronized.
Loss of inactive Redolog files
If redo logs are lost recovery to the time of failure is not possible but if lost redologs are not current, the redolog has been archived and proper mulltiplexing of redo logs are available no data will be lost.
Scenario 7
Check V$Logfile for current logfile and delete one fo the redlog file which is not current.
Using operating system. Force the log switch
> Alter system switch logfile;
it will give an eror
ORA- 00313 : open failed for members of log group of thread 1
Incomplete Recovery
In incomplete recovery database will be recovered before the time of failure.
Possible Failures : A failed complete recovery operation, Important table in the Database is dropped, A control file is lost, Loss of redolog files
Rquirement : Valid online or offline backup of all the database files.
Need all archived logs ,Back up of control file.
Recovery : Shutdown and backup the database.
Restore all data files.
Do not restore the control file, redo logs, password files, or
Parameter files.
Mount the database and recover the data file before time of failure.
Perform a closed database backup.
Recovery Guidelines :
· Follow all steps: Most errors occur during this type of recovery.
· Whole-database backup before and after recovery assist future recovery.
· Always verify that the recovery is successful.
· Back up the control file regularly.
· Back up and remove archived logs.
· Database are brought forward in time, not bake in time.
Time based recovery
Scenerio 8 : A table is dropped at 10 am at 11 am user comes to know that the table view or table does not exist
Create a table test.
> Create table test ( n number );
Insert values
> Insert into test values (11111);
> Commit ; > Alter system switch logfile ; Note down the commit timing. Give some time gap and drop the table
> Drop table test ;
Shutdown the database
> Shutdown
Mount the databse
> Startup mount ; Restore all datafile from backup (most recent ) using operating system. And recover the database until time (Specify time before droping the table )
> Recover database until time ‘2001-11-12:09:30:00’; > Alter database open resetlogs ; After incomplete recovery take new backup of database.
Select * from nls_database_parameter;
Cancel based recovery
Scenario 9 : Lost a redolog file
Shutdown the database.
Take back up of all logfiles, datafiles, controlfiles
Delete one log file using operating system.
Mount the database
> startup mount ;
Restore all datafile from backup using system.
> recover database until cancel ;
> Alter database open resetlogs ;
Check for log file in v$ logfile
Change based recovery
Scenerio 10 : No back up was taken after reset logs, need is to use cold backup
Backup the data file and control file. ( cold backup )
Perform incomplete recovery ( To bring database in new incarnation you can recover by time based or cancel based )
Create a table insert some records commit. Shutdown the database.
> Shutdown
Restore cold data file and control file ( from cold backup)
Startup the database. ( You will get an error )
> Startup
Check V$Log for change seq #)
Recover until Change
> recover database until change <>;
> Alter database open resetlog :
Check for table created.
Scenerio 11
Recovery using backup controlfile
Tablespace was created at 10am and backup was taken and dropped at 2pm
Create a tablespace and create one table insert records into the table.
Take backup of all datafile and controlfile ( closed/open if you are taking open database backup first take backup of controlfile than datafile )
Drop the tablespace.
> Drop tablespace test including contents ;
Shutdown the database take backup of existing controlfile first than restore controlfile and datafile.
Startup the database it will give an error after taking the database in mount stage.
Make sure that all datafiles are online before recovery by checking v$recover_file Perform recovery using backup controlfile
> recover database until time ‘2001-11-11:13:10:00’ using backup controlfile;
> Alter database open resetlogs ; Check for the table.
Scenario 12
Backup was taken of both controlfile and datafile at 10 am. At 11 am Tablespace was created and at 1pm tablespace was dropped. Recover the tablespace using cold backup.
Scenario 13
A table test was created at 10am and dropped at 10.30 am, another table test1 was dropped at 10.45am. Recover the tables without losing any records in both the table.
Scenario 14
Recover the lost current control file, or the current control file is inconsistent with files that you need to recover
Scenario 15
Recover lost online redo logs.
Scenario 16
Recover new information that was not in the backup and was only stored in the archivelog files.
Scenario 17
How to recover a database having added a datafile since the last backup.
Scenario 18
If the database crashes during a hot backup.
source and reference:
http://halimdba.blogspot.com/2009/02/backup-seneries.html
Monday, November 16, 2009
Monitoring the Primary and Standby Databases
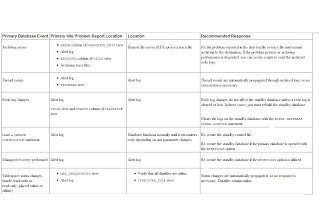
Table indicates whether a primary database event is automatically administered by log transport services and log apply services or requires additional intervention by the database administrator (DBA) to be propagated to the standby database. It also describes how to respond to these events.
Troubleshooting Primary Database Events
regards,
rajeshkumar govindarajan.
source and reference:
http://www-css.fnal.gov/dsg/external/oracle_dcm/9iv2/server.920/a96653/sbydb_manage_ps.htm#1005701
related topics
# Dynamic Performance Views (Fixed Views)For Manganing Standby Database
# Determining Which Logs Have Been Applied to the Standby Database
# Determining Which Logs Have Not Been Received by the Standby Site
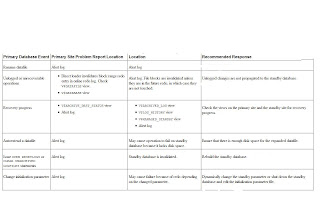
Troubleshooting Primary Database Events


regards,
rajeshkumar govindarajan.
source and reference:
http://www-css.fnal.gov/dsg/external/oracle_dcm/9iv2/server.920/a96653/sbydb_manage_ps.htm#1005701
related topics
# Dynamic Performance Views (Fixed Views)For Manganing Standby Database
# Determining Which Logs Have Been Applied to the Standby Database
# Determining Which Logs Have Not Been Received by the Standby Site
Determining Which Logs Have Been Applied to the Standby Database
Query the V$LOG_HISTORY view on the standby database, which records the latest log sequence number that has been applied. For example, issue the following query:
SQL> SELECT THREAD#, MAX(SEQUENCE#) AS "LAST_APPLIED_LOG"
2> FROM V$LOG_HISTORY
3> GROUP BY THREAD#;
THREAD# LAST_APPLIED_LOG
------- ----------------
1 967
In this example, the archived redo log with log sequence number 967 is the most recently applied log.
You can also use the APPLIED column in the V$ARCHIVED_LOG fixed view on the standby database to find out which log is applied on the standby database. The column displays YES for the log that has been applied. For example:
SQL> SELECT THREAD#, SEQUENCE#, APPLIED FROM V$ARCHIVED_LOG;
THREAD# SEQUENCE# APP
---------- ---------- ---
1 2 YES
1 3 YES
1 4 YES
1 5 YES
1 6 YES
1 7 YES
1 8 YES
1 9 YES
1 10 YES
1 11 NO
10 rows selected.
regards,
rajeshkumar govindarajan.
source and reference:
http://www-css.fnal.gov/dsg/external/oracle_dcm/9iv2/server.920/a96653/sbydb_manage_ps.htm#1005911
related topics:
Determining Which Logs Have Not Been Received by the Standby Site
Dynamic Performance Views (Fixed Views) for managing standby database
SQL> SELECT THREAD#, MAX(SEQUENCE#) AS "LAST_APPLIED_LOG"
2> FROM V$LOG_HISTORY
3> GROUP BY THREAD#;
THREAD# LAST_APPLIED_LOG
------- ----------------
1 967
In this example, the archived redo log with log sequence number 967 is the most recently applied log.
You can also use the APPLIED column in the V$ARCHIVED_LOG fixed view on the standby database to find out which log is applied on the standby database. The column displays YES for the log that has been applied. For example:
SQL> SELECT THREAD#, SEQUENCE#, APPLIED FROM V$ARCHIVED_LOG;
THREAD# SEQUENCE# APP
---------- ---------- ---
1 2 YES
1 3 YES
1 4 YES
1 5 YES
1 6 YES
1 7 YES
1 8 YES
1 9 YES
1 10 YES
1 11 NO
10 rows selected.
regards,
rajeshkumar govindarajan.
source and reference:
http://www-css.fnal.gov/dsg/external/oracle_dcm/9iv2/server.920/a96653/sbydb_manage_ps.htm#1005911
related topics:
Determining Which Logs Have Not Been Received by the Standby Site
Dynamic Performance Views (Fixed Views) for managing standby database
Determining Which Logs Have Not Been Received by the Standby Site
Each archive destination has a destination ID assigned to it. You can query the DEST_ID column in the V$ARCHIVE_DEST fixed view to find out your destination ID. You can then use this destination ID in a query on the primary database to discover logs that have not been sent to a particular standby site.
For example, assume the current local archive destination ID on your primary database is 1, and the destination ID of one of your remote standby databases is 2. To find out which logs have not been received by this standby destination, issue the following query on the primary database:
SQL> SELECT LOCAL.THREAD#, LOCAL.SEQUENCE# FROM
2> (SELECT THREAD#, SEQUENCE# FROM V$ARCHIVED_LOG WHERE DEST_ID=1) LOCAL
3> WHERE
4> LOCAL.SEQUENCE# NOT IN
5> (SELECT SEQUENCE# FROM V$ARCHIVED_LOG WHERE DEST_ID=2 AND
6> THREAD# = LOCAL.THREAD#);
THREAD# SEQUENCE#
---------- ----------
1 12
1 13
1 14
The preceding example shows the logs that have not yet been received by standby destination 2.
regards,
rajeshkumar govindarajan
source and reference:
http://www-css.fnal.gov/dsg/external/oracle_dcm/9iv2/server.920/a96653/sbydb_manage_ps.htm#1005941
related topics:
Dyanamic performance views for managing standby database
Determine which Log Have Been Applied to the standby database
For example, assume the current local archive destination ID on your primary database is 1, and the destination ID of one of your remote standby databases is 2. To find out which logs have not been received by this standby destination, issue the following query on the primary database:
SQL> SELECT LOCAL.THREAD#, LOCAL.SEQUENCE# FROM
2> (SELECT THREAD#, SEQUENCE# FROM V$ARCHIVED_LOG WHERE DEST_ID=1) LOCAL
3> WHERE
4> LOCAL.SEQUENCE# NOT IN
5> (SELECT SEQUENCE# FROM V$ARCHIVED_LOG WHERE DEST_ID=2 AND
6> THREAD# = LOCAL.THREAD#);
THREAD# SEQUENCE#
---------- ----------
1 12
1 13
1 14
The preceding example shows the logs that have not yet been received by standby destination 2.
regards,
rajeshkumar govindarajan
source and reference:
http://www-css.fnal.gov/dsg/external/oracle_dcm/9iv2/server.920/a96653/sbydb_manage_ps.htm#1005941
related topics:
Dyanamic performance views for managing standby database
Determine which Log Have Been Applied to the standby database
Monitoring Events That Affect the Standby Database
To prevent possible problems, you should be aware of events that affect a standby database and learn how to monitor them. Most changes to a primary database are automatically propagated to a standby database through archived redo logs and thus require no user intervention. Nevertheless, some changes to a primary database require manual intervention at the standby site.
Dynamic Performance Views (Fixed Views)
The Oracle database server contains a set of underlying views that are maintained by the server. These views are often called dynamic performance views because they are continuously updated while a database is open and in use, and their contents relate primarily to performance. These views are also called fixed views, because they cannot be altered or removed by the database administrator.
These view names are prefixed with either V$ or GV$, for example, V$ARCHIVE_DEST or GV$ARCHIVE_DEST.
Standard dynamic performance views (V$ fixed views) store information on the local instance. In contrast, global dynamic performance views (GV$ fixed views), store information on all open instances. Each V$ fixed view has a corresponding GV$ fixed view.
The following fixed views contain useful information for monitoring the Data Guard environment:
* V$ARCHIVE_DEST
Describes the archived redo log destinations associated with the current instance on the primary site. You can use this view to find out the current settings of your archived redo log destinations.
* V$ARCHIVE_DEST_STATUS
This view, an extension of the V$ARCHIVE_DEST view, displays runtime and configuration information for the archived redo log destinations. You can use this view to determine the progress of archiving to each destination. It also shows the current status of the archive destination.
* V$ARCHIVE_GAP
Provides information about archive gaps on a standby database. You can use this view to find out the current archive gap that is blocking recovery.
* V$ARCHIVED_LOG
Displays archived redo log information from the control file, including archived log names. This view gives you information on which log has been archived to where on your primary database. On the primary database, this view describes the logs archived to both the local and remote destinations. On a standby database, this view provides information about the logs archived to this standby database. You can use this fixed view to help you to track archiving progress to the standby system by viewing the applied field.
* V$DATABASE
Contains database information from the control file. You can use this view to quickly find out if your database is a primary or a standby database, as well as its switchover status and standby database protection mode.
* V$DATAFILE
Contains datafile information from the control file. You can query this fixed view to verify that the standby datafiles are correctly renamed after your standby database is re-created.
* V$DATAGUARD_STATUS
Displays and logs events related to Data Guard since the instance was started.
* V$LOG
Contains log file information from the online redo logs. You can use the information about the current online log on the primary database from this view as a reference point to determine how far behind your standby database is in receiving and applying logs.
* V$LOGFILE
Contains static information about the online redo logs and standby redo logs.
* V$LOG_HISTORY
Contains log history information from the control file, including a record of the latest archived log that was applied.
* V$MANAGED_STANDBY
Displays current and status information for some Oracle database server processes related to Data Guard. This view can show both foreground and background processes. You can use this view to monitor the various Data Guard recovery and archiving processes on the standby system.
* V$STANDBY_LOG
Provides information about the standby redo logs. Standby redo logs are similar to online redo logs, but they are only used on a standby database receiving logs from the primary database using the log writer process.
regards,
rajeshkumar govindarajan
source and reference:
http://www-css.fnal.gov/dsg/external/oracle_dcm/9iv2/server.920/a96653/sbydb_manage_ps.htm
related topics:
Determining Which Logs Have Not Been Received by the Standby Site
Dynamic Performance Views (Fixed Views)
The Oracle database server contains a set of underlying views that are maintained by the server. These views are often called dynamic performance views because they are continuously updated while a database is open and in use, and their contents relate primarily to performance. These views are also called fixed views, because they cannot be altered or removed by the database administrator.
These view names are prefixed with either V$ or GV$, for example, V$ARCHIVE_DEST or GV$ARCHIVE_DEST.
Standard dynamic performance views (V$ fixed views) store information on the local instance. In contrast, global dynamic performance views (GV$ fixed views), store information on all open instances. Each V$ fixed view has a corresponding GV$ fixed view.
The following fixed views contain useful information for monitoring the Data Guard environment:
* V$ARCHIVE_DEST
Describes the archived redo log destinations associated with the current instance on the primary site. You can use this view to find out the current settings of your archived redo log destinations.
* V$ARCHIVE_DEST_STATUS
This view, an extension of the V$ARCHIVE_DEST view, displays runtime and configuration information for the archived redo log destinations. You can use this view to determine the progress of archiving to each destination. It also shows the current status of the archive destination.
* V$ARCHIVE_GAP
Provides information about archive gaps on a standby database. You can use this view to find out the current archive gap that is blocking recovery.
* V$ARCHIVED_LOG
Displays archived redo log information from the control file, including archived log names. This view gives you information on which log has been archived to where on your primary database. On the primary database, this view describes the logs archived to both the local and remote destinations. On a standby database, this view provides information about the logs archived to this standby database. You can use this fixed view to help you to track archiving progress to the standby system by viewing the applied field.
* V$DATABASE
Contains database information from the control file. You can use this view to quickly find out if your database is a primary or a standby database, as well as its switchover status and standby database protection mode.
* V$DATAFILE
Contains datafile information from the control file. You can query this fixed view to verify that the standby datafiles are correctly renamed after your standby database is re-created.
* V$DATAGUARD_STATUS
Displays and logs events related to Data Guard since the instance was started.
* V$LOG
Contains log file information from the online redo logs. You can use the information about the current online log on the primary database from this view as a reference point to determine how far behind your standby database is in receiving and applying logs.
* V$LOGFILE
Contains static information about the online redo logs and standby redo logs.
* V$LOG_HISTORY
Contains log history information from the control file, including a record of the latest archived log that was applied.
* V$MANAGED_STANDBY
Displays current and status information for some Oracle database server processes related to Data Guard. This view can show both foreground and background processes. You can use this view to monitor the various Data Guard recovery and archiving processes on the standby system.
* V$STANDBY_LOG
Provides information about the standby redo logs. Standby redo logs are similar to online redo logs, but they are only used on a standby database receiving logs from the primary database using the log writer process.
regards,
rajeshkumar govindarajan
source and reference:
http://www-css.fnal.gov/dsg/external/oracle_dcm/9iv2/server.920/a96653/sbydb_manage_ps.htm
related topics:
Determining Which Logs Have Not Been Received by the Standby Site
Sunday, November 15, 2009
Static data dictionary views
The following views are part of the data dictionary.
Find all views along with a comment in dict:
select * from dict;
USER_ / ALL_ / DBA_
Most static dictionary views come with three prefixes: USER_*, ALL_* and DBA_*. For example, there's a user_tables, all_tables and a dba_tables view. For brevity, I only give the names of the views that start with dba_.
Generally, the user_ views show database objects owned by the user who is querying the user_ view.
The all_ views show the database objects that are accessible to the user who is querying the all_view.
The dba_ views show all database objects.
Table related data dictionary views
* dba_tables
* dba_tab_columns
* dba_all_tables
* dba_tab_comments
* dba_col_comments
* dba_external_tables
* dba_external_locations
* dba_tab_histograms
* dba_tab_statistics
* dba_tab_col_statistics
* dba_tab_modifications
* dba_encrypted_columns
* dba_unused_col_tabs
* dba_partial_drop_tabs
Registry related data dictionary views
* dba_registry,
* dba_registry_hierarchy,
* dba_registry_history,
* dba_registry_log
XML DB related views
* dba_xml_schemas
* dba_xml_tables
* dba_xml_views
* dba_xml_views_cols
Audit related views
* dba_audit_exists
* dba_audit_object
* dba_audit_policies
* dba_audit_policy_columns
* dba_audit_session
* dba_audit_statement
* dba_audit_trail
* dba_common_audit_trail
* dba_fga_audit_trail
* dba_opj_audit_opts
* dba_priv_audit_opts
* dba_repaudit_attribute
* dba_repaudit_column
* dba_stmt_audit_option_opts
Other static data dictionary views
dba_advisor_findings
Exposes the Oracle 10g's advisors tips.
See also dbms_sqltune
dba_advisor_recommendations
Exposes the Oracle 10g's advisors tips.
See also dbms_sqltune
dba_advisor_rationale
Exposes the Oracle 10g's advisors tips.
See also dbms_sqltune
dba_advisor_tasks
Exposes the Oracle 10g's advisors tips.
See also dbms_sqltune
dba_arguments
This view can be used to find out what arguments a procedure's or object type's function/procedure has.
See this page for an example of a select statement, or this pagea.
dba_col_privs
dba_constraints
Derives from con$. Records the constraints.
See also On identifiying parent and child tables.
dba_datapump_jobs
This view monitors data pump jobs.
dba_data_files
If a datafile has autoextend on and unlimited maxsize, the maxsize is reported with a ridiciculous high number such as 1.7180E+10.
file_id vs relative_fno: file_id is unique in a database while relative_fno is 'only' unique for datafiles within a tablespace.
dba_db_links
dba_directories
Displays all directories that were created with create directory.
Note: There's no user_directories, only dba_directories and all_directories exist!
defcall
This is a view that belongs to the replication catalog.
defdefaultdest
This is a view that belongs to the replication catalog.
deferror
This is a view that belongs to the replication catalog.
It records entries in the error queue.
defpropagator
This is a view that belongs to the replication catalog.
deftran
This is a view that belongs to the replication catalog.
defcalldest
This is a view that belongs to the replication catalog.
deferrcount
This is a view that belongs to the replication catalog.
deflob
This is a view that belongs to the replication catalog.
defschedule
This is a view that belongs to the replication catalog.
deftrandest
This is a view that belongs to the replication catalog.
Use dbms_defer_sys.delete_tran to get rid of entries in deftrandest.
This view records entries in the deferred transaction queue.
flashback_transaction_query
Used for Flashback transaction queries. (See flashback transaction query example)
global_name
dba_indexes
dba_jobs
dba_jobs_running
dba_lobs
dba_logstdby_log
Can be used to verirfy that archived redo log are being applied to standby databases.
dba_logstdby_not_unique
dba_logstdby_parameters
dba_logstdby_progress
dba_logstdby_skip
dba_logstdby_skip_transaction
dba_mviews
dba_objects
Displays information about objects.
all_olap2_aw_cubes
Shows all cubes in all analytic workspaces.
all_olap2_aw_dimensions
dba_plsql_object_settings
Stores the values of the following initialization parameters as of compilation time:
* plsql_ccflags
* plsql_code_type
* plsql_debug
* plsql_optimize_level
* plsql_warnings
* nls_length_semantics
dba_procedures
The column procedure_name is null for procedures and functions, it is only set for procedures and functions in pl/sql packages. The procedures' and functions' names are found in the column object_name, however, using dba_procedures, it is not possible to find out if it is a procedure or function. This is possible with dba_objects.
dba_profiles
Allows to see the profiles and their settings.
dba_queues
dba_queue_tables
See drop table.
dba_recyclebin
Displays the object in the recycle bin for the currently logged on user.
recyclebin is a synonym for user_recyclebin.
dba_refresh
dba_registered_mview_groups
This is a view that belongs to the replication catalog.
See also materialized view group.
dba_registry
dba_repcat_refresh_templates
This is a view that belongs to the replication catalog.
dba_repcat_template_objects
This is a view that belongs to the replication catalog.
It keeps track of deployent templates.
dba_repcat_template_parms
This is a view that belongs to the replication catalog.
dba_repcat_template_sites
This is a view that belongs to the replication catalog.
dba_repcat_user_authorizations
This is a view that belongs to the replication catalog.
dba_repcat_user_parm_values
This is a view that belongs to the replication catalog.
dba_repcatlog
This is a view that belongs to the replication catalog.
It can be used to track administrative requests.
dba_repcolumn
This is a view that belongs to the replication catalog.
dba_repcolumn_group
This is a view that belongs to the replication catalog.
dba_repconflict
This is a view that belongs to the replication catalog.
dba_repddl
This is a view that belongs to the replication catalog.
dba_repextensions
This is a view that belongs to the replication catalog.
dba_repgenobjects
This is a view that belongs to the replication catalog.
dba_repgroup
This is a view that belongs to the replication catalog.
dba_repgroup_privileges
This is a view that belongs to the replication catalog.
dba_repgrouped_column
This is a view that belongs to the replication catalog.
dba_repkey_columns
This is a view that belongs to the replication catalog.
dba_repobject
This is a view that belongs to the replication catalog.
dba_repparameter_column
This is a view that belongs to the replication catalog.
dba_reppriority
This is a view that belongs to the replication catalog.
dba_reppriority_group
This is a view that belongs to the replication catalog.
dba_repprop
This is a view that belongs to the replication catalog.
dba_represol_stats_control
This is a view that belongs to the replication catalog.
dba_represolution
This is a view that belongs to the replication catalog.
dba_represolution_method
This is a view that belongs to the replication catalog.
dba_represolution_statistics
This is a view that belongs to the replication catalog.
dba_repsites
This is a view that belongs to the replication catalog.
dba_repsites_new
This is a view that belongs to the replication catalog.
dba_rewrite_equivalences
This view can be used to show the equivalences that were established using dbms_advanced_rewrite.declare_rewrite_equivalence.
dba_roles
This view lists all roles except the special role public.
select name, ##A(decode/ora/sql/decode.html)(password, null, 'NO', 'EXTERNAL', 'EXTERNAL',
'GLOBAL', 'GLOBAL', 'YES')
from user$
where type# = 0 and name not in ('PUBLIC', '_NEXT_USER')
dba_role_privs
Lists roles that are assigned to a either another role or a user.
Here is a script that uses dba_role_privs to recursively list privileges assigned to users and roles.
dba_segments
This view shows information about segments.
dba_sequences
dba_sequences is a bit special: Unlike dba_tables, dba_indexes, dba_triggers, dba_constraints, dba_db_links, dba_jobs, dba_queue_tables and dba_queues, there is no column owner but sequence_owner.
dba_source
dba_sqltune_binds
This view can be used to get the SQL tuning advisors recommondations.
dba_sqltune_plans
This view can be used to get the SQL tuning advisors recommondations.
dba_sqltune_statistics
This view can be used to get the SQL tuning advisors recommondations.
dba_synonyms
Show all synonyms.
dba_sys_privs
Lists system privileges that are assigned to a either another role or a user.
dba_scheduler_job_run_details
system_privilege_map
Lists all system privileges.
These privileges can be audited.
all_sumdelta
Lists direct path load entries accessible to the current user.
dba_tab_privs
all_tab_privs_made
There is no dba_tab_privs_made, only user_tab_privs_made and all_tab_privs_made.
All_tab_privs_made view lists all object privileges that the current either has granted or for for which he owns the underlying object.
User_tab_privs_made displays only grants for which the current user is the object owner.
These views are not role-recursive. That is to say, if I grant an object privilege to a role, and then grant that role to a user, this view doesn't show me that the user has that object's privilege.
A related view is all_tab_privs_recd.
all_tab_privs_recd
There is no dba_tab_privs_recd, only user_tab_privs_recd and all_tab_privs_recd.
A related view is all_tab_privs_made.
dba_triggers
See also Getting the nth source code line of a trigger.
dba_ts_quotas
Can be used to find out how big the quota of a user is on a tablespace and how much thereof he has already occupied.
dba_users
Has a record for each user in the database.
The related view user_users has only one row: the one that belongs to the user selecting from user_users. See also Who am I.
dba_tablespaces
Displays the tablespaces of a database.
dba_views
regards,
rajeshkumar govindarajan
source and reference:
http://www.adp-gmbh.ch/ora/misc/static_dictionary_views.html
Find all views along with a comment in dict:
select * from dict;
USER_ / ALL_ / DBA_
Most static dictionary views come with three prefixes: USER_*, ALL_* and DBA_*. For example, there's a user_tables, all_tables and a dba_tables view. For brevity, I only give the names of the views that start with dba_.
Generally, the user_ views show database objects owned by the user who is querying the user_ view.
The all_ views show the database objects that are accessible to the user who is querying the all_view.
The dba_ views show all database objects.
Table related data dictionary views
* dba_tables
* dba_tab_columns
* dba_all_tables
* dba_tab_comments
* dba_col_comments
* dba_external_tables
* dba_external_locations
* dba_tab_histograms
* dba_tab_statistics
* dba_tab_col_statistics
* dba_tab_modifications
* dba_encrypted_columns
* dba_unused_col_tabs
* dba_partial_drop_tabs
Registry related data dictionary views
* dba_registry,
* dba_registry_hierarchy,
* dba_registry_history,
* dba_registry_log
XML DB related views
* dba_xml_schemas
* dba_xml_tables
* dba_xml_views
* dba_xml_views_cols
Audit related views
* dba_audit_exists
* dba_audit_object
* dba_audit_policies
* dba_audit_policy_columns
* dba_audit_session
* dba_audit_statement
* dba_audit_trail
* dba_common_audit_trail
* dba_fga_audit_trail
* dba_opj_audit_opts
* dba_priv_audit_opts
* dba_repaudit_attribute
* dba_repaudit_column
* dba_stmt_audit_option_opts
Other static data dictionary views
dba_advisor_findings
Exposes the Oracle 10g's advisors tips.
See also dbms_sqltune
dba_advisor_recommendations
Exposes the Oracle 10g's advisors tips.
See also dbms_sqltune
dba_advisor_rationale
Exposes the Oracle 10g's advisors tips.
See also dbms_sqltune
dba_advisor_tasks
Exposes the Oracle 10g's advisors tips.
See also dbms_sqltune
dba_arguments
This view can be used to find out what arguments a procedure's or object type's function/procedure has.
See this page for an example of a select statement, or this pagea.
dba_col_privs
dba_constraints
Derives from con$. Records the constraints.
See also On identifiying parent and child tables.
dba_datapump_jobs
This view monitors data pump jobs.
dba_data_files
If a datafile has autoextend on and unlimited maxsize, the maxsize is reported with a ridiciculous high number such as 1.7180E+10.
file_id vs relative_fno: file_id is unique in a database while relative_fno is 'only' unique for datafiles within a tablespace.
dba_db_links
dba_directories
Displays all directories that were created with create directory.
Note: There's no user_directories, only dba_directories and all_directories exist!
defcall
This is a view that belongs to the replication catalog.
defdefaultdest
This is a view that belongs to the replication catalog.
deferror
This is a view that belongs to the replication catalog.
It records entries in the error queue.
defpropagator
This is a view that belongs to the replication catalog.
deftran
This is a view that belongs to the replication catalog.
defcalldest
This is a view that belongs to the replication catalog.
deferrcount
This is a view that belongs to the replication catalog.
deflob
This is a view that belongs to the replication catalog.
defschedule
This is a view that belongs to the replication catalog.
deftrandest
This is a view that belongs to the replication catalog.
Use dbms_defer_sys.delete_tran to get rid of entries in deftrandest.
This view records entries in the deferred transaction queue.
flashback_transaction_query
Used for Flashback transaction queries. (See flashback transaction query example)
global_name
dba_indexes
dba_jobs
dba_jobs_running
dba_lobs
dba_logstdby_log
Can be used to verirfy that archived redo log are being applied to standby databases.
dba_logstdby_not_unique
dba_logstdby_parameters
dba_logstdby_progress
dba_logstdby_skip
dba_logstdby_skip_transaction
dba_mviews
dba_objects
Displays information about objects.
all_olap2_aw_cubes
Shows all cubes in all analytic workspaces.
all_olap2_aw_dimensions
dba_plsql_object_settings
Stores the values of the following initialization parameters as of compilation time:
* plsql_ccflags
* plsql_code_type
* plsql_debug
* plsql_optimize_level
* plsql_warnings
* nls_length_semantics
dba_procedures
The column procedure_name is null for procedures and functions, it is only set for procedures and functions in pl/sql packages. The procedures' and functions' names are found in the column object_name, however, using dba_procedures, it is not possible to find out if it is a procedure or function. This is possible with dba_objects.
dba_profiles
Allows to see the profiles and their settings.
dba_queues
dba_queue_tables
See drop table.
dba_recyclebin
Displays the object in the recycle bin for the currently logged on user.
recyclebin is a synonym for user_recyclebin.
dba_refresh
dba_registered_mview_groups
This is a view that belongs to the replication catalog.
See also materialized view group.
dba_registry
dba_repcat_refresh_templates
This is a view that belongs to the replication catalog.
dba_repcat_template_objects
This is a view that belongs to the replication catalog.
It keeps track of deployent templates.
dba_repcat_template_parms
This is a view that belongs to the replication catalog.
dba_repcat_template_sites
This is a view that belongs to the replication catalog.
dba_repcat_user_authorizations
This is a view that belongs to the replication catalog.
dba_repcat_user_parm_values
This is a view that belongs to the replication catalog.
dba_repcatlog
This is a view that belongs to the replication catalog.
It can be used to track administrative requests.
dba_repcolumn
This is a view that belongs to the replication catalog.
dba_repcolumn_group
This is a view that belongs to the replication catalog.
dba_repconflict
This is a view that belongs to the replication catalog.
dba_repddl
This is a view that belongs to the replication catalog.
dba_repextensions
This is a view that belongs to the replication catalog.
dba_repgenobjects
This is a view that belongs to the replication catalog.
dba_repgroup
This is a view that belongs to the replication catalog.
dba_repgroup_privileges
This is a view that belongs to the replication catalog.
dba_repgrouped_column
This is a view that belongs to the replication catalog.
dba_repkey_columns
This is a view that belongs to the replication catalog.
dba_repobject
This is a view that belongs to the replication catalog.
dba_repparameter_column
This is a view that belongs to the replication catalog.
dba_reppriority
This is a view that belongs to the replication catalog.
dba_reppriority_group
This is a view that belongs to the replication catalog.
dba_repprop
This is a view that belongs to the replication catalog.
dba_represol_stats_control
This is a view that belongs to the replication catalog.
dba_represolution
This is a view that belongs to the replication catalog.
dba_represolution_method
This is a view that belongs to the replication catalog.
dba_represolution_statistics
This is a view that belongs to the replication catalog.
dba_repsites
This is a view that belongs to the replication catalog.
dba_repsites_new
This is a view that belongs to the replication catalog.
dba_rewrite_equivalences
This view can be used to show the equivalences that were established using dbms_advanced_rewrite.declare_rewrite_equivalence.
dba_roles
This view lists all roles except the special role public.
select name, ##A(decode/ora/sql/decode.html)(password, null, 'NO', 'EXTERNAL', 'EXTERNAL',
'GLOBAL', 'GLOBAL', 'YES')
from user$
where type# = 0 and name not in ('PUBLIC', '_NEXT_USER')
dba_role_privs
Lists roles that are assigned to a either another role or a user.
Here is a script that uses dba_role_privs to recursively list privileges assigned to users and roles.
dba_segments
This view shows information about segments.
dba_sequences
dba_sequences is a bit special: Unlike dba_tables, dba_indexes, dba_triggers, dba_constraints, dba_db_links, dba_jobs, dba_queue_tables and dba_queues, there is no column owner but sequence_owner.
dba_source
dba_sqltune_binds
This view can be used to get the SQL tuning advisors recommondations.
dba_sqltune_plans
This view can be used to get the SQL tuning advisors recommondations.
dba_sqltune_statistics
This view can be used to get the SQL tuning advisors recommondations.
dba_synonyms
Show all synonyms.
dba_sys_privs
Lists system privileges that are assigned to a either another role or a user.
dba_scheduler_job_run_details
system_privilege_map
Lists all system privileges.
These privileges can be audited.
all_sumdelta
Lists direct path load entries accessible to the current user.
dba_tab_privs
all_tab_privs_made
There is no dba_tab_privs_made, only user_tab_privs_made and all_tab_privs_made.
All_tab_privs_made view lists all object privileges that the current either has granted or for for which he owns the underlying object.
User_tab_privs_made displays only grants for which the current user is the object owner.
These views are not role-recursive. That is to say, if I grant an object privilege to a role, and then grant that role to a user, this view doesn't show me that the user has that object's privilege.
A related view is all_tab_privs_recd.
all_tab_privs_recd
There is no dba_tab_privs_recd, only user_tab_privs_recd and all_tab_privs_recd.
A related view is all_tab_privs_made.
dba_triggers
See also Getting the nth source code line of a trigger.
dba_ts_quotas
Can be used to find out how big the quota of a user is on a tablespace and how much thereof he has already occupied.
dba_users
Has a record for each user in the database.
The related view user_users has only one row: the one that belongs to the user selecting from user_users. See also Who am I.
dba_tablespaces
Displays the tablespaces of a database.
dba_views
regards,
rajeshkumar govindarajan
source and reference:
http://www.adp-gmbh.ch/ora/misc/static_dictionary_views.html
SYS owned tables [Base tables of the Oracle dictionary]
These tables are the base tables in the data dictionary. Their content is exposed for easier access through SQL through the static dictionary views.
aud$
See auditing and audit (sql).
aux_stats$
pname can take several values, the most usefull beeing:
* MBRC
* SREADTIM
* MREADTIM
* CPUSPEED - In MHz, obviously not always right
* SLAVETHR - Throughput
* ????THR
* BADSTAT(S)
col$
col_usage$
This table allows to monitor the usage of predicates on columns in select statements.
It is updated (if _column_tracking_level is set to 1) at intervalls by smon, so it might be a little out of date.
Also, dbms_stats will make use of that info when deciding if it needs to create a histogram on a column.
select
o.name,
c.name,
u.equality_preds,
u.equijoin_preds,
u.nonequijoin_preds,
u.range_preds,
u.like_preds,
u.null_preds
from
sys.col_usage$ u
join sys.obj$ o on u.obj# = o.obj#
join sys.col$ c on u.obj# = c.obj# and u.intcol# = c.col#;
con$
This table keeps track of constraints. dba_constraints derive from this table.
dbms_lock_allocated
This table stores a row for each lock allocated with dbms_lock.allocate_unique.
fet$
In dictionary managed tablespaces, free extents are maintained in fet$. See also uet$
mlog$
See also refreshing a materialized view.
obj$
Lists all objects created in a database.
The following statement lists all objects created for the current loged on user:
select * from sys.obj$ where owner# = userenv('SCHEMAID')
prop$
rgroup$
session_privs
This view lists the selecting user's privileges.
See also this page.
slog$
See also refreshing a materialized view.
snap$
See also refreshing a materialized view.
smon_scn_time
smon_scn_time is a table that is filled by SMON every 5 minutes with a timestamp and the current SCN. However, it only counts 1440 records (=5 days). This makes it possible to roughly find an SCN for a point in time in the last 5 days.
This table is not documented, so only look at it out of curiosity.
uet$
In dictionary managed tablespaces, extents are maintained in uet$. See also fet$
user$
Contains two types (column type#) of objects: users (type# = 1) and roles (type# = 0).
user_history$
This table is important to store the history of passwords for a user if password related profiles are enabled.
regards,
rajeshkumar
source and reference:
http://www.adp-gmbh.ch/ora/misc/sys_tables.html
aud$
See auditing and audit (sql).
aux_stats$
pname can take several values, the most usefull beeing:
* MBRC
* SREADTIM
* MREADTIM
* CPUSPEED - In MHz, obviously not always right
* SLAVETHR - Throughput
* ????THR
* BADSTAT(S)
col$
col_usage$
This table allows to monitor the usage of predicates on columns in select statements.
It is updated (if _column_tracking_level is set to 1) at intervalls by smon, so it might be a little out of date.
Also, dbms_stats will make use of that info when deciding if it needs to create a histogram on a column.
select
o.name,
c.name,
u.equality_preds,
u.equijoin_preds,
u.nonequijoin_preds,
u.range_preds,
u.like_preds,
u.null_preds
from
sys.col_usage$ u
join sys.obj$ o on u.obj# = o.obj#
join sys.col$ c on u.obj# = c.obj# and u.intcol# = c.col#;
con$
This table keeps track of constraints. dba_constraints derive from this table.
dbms_lock_allocated
This table stores a row for each lock allocated with dbms_lock.allocate_unique.
fet$
In dictionary managed tablespaces, free extents are maintained in fet$. See also uet$
mlog$
See also refreshing a materialized view.
obj$
Lists all objects created in a database.
The following statement lists all objects created for the current loged on user:
select * from sys.obj$ where owner# = userenv('SCHEMAID')
prop$
rgroup$
session_privs
This view lists the selecting user's privileges.
See also this page.
slog$
See also refreshing a materialized view.
snap$
See also refreshing a materialized view.
smon_scn_time
smon_scn_time is a table that is filled by SMON every 5 minutes with a timestamp and the current SCN. However, it only counts 1440 records (=5 days). This makes it possible to roughly find an SCN for a point in time in the last 5 days.
This table is not documented, so only look at it out of curiosity.
uet$
In dictionary managed tablespaces, extents are maintained in uet$. See also fet$
user$
Contains two types (column type#) of objects: users (type# = 1) and roles (type# = 0).
user_history$
This table is important to store the history of passwords for a user if password related profiles are enabled.
regards,
rajeshkumar
source and reference:
http://www.adp-gmbh.ch/ora/misc/sys_tables.html
Dynamic Performance Views
Oracle's V$ Views
v$archive_dest
Shows all archived redo log destinations. Use this view to find out to which place archived redo logs are copied: select dest_id,destination from v$archive_dest
These values correspond to the init parameter log_archive_dest_n.
v$archive_dest_status
This view allows to find status and errors for each of the defined
v$archived_log
Displays successfully archived redo logs.
shows received logs on a primary standby database.
v$archive_gap
Lists sequence numbers of the archived los that are known to be missing for each thread on a (physical?) standby database (highest gap only).
v$archive_processes
This view provides information on the archive processes. It can be used to find out if an ARCH process is active or not.
v$controlfile
Displays the location and status of each controlfile in the database.
v$controlfile_record_section
See sections in a controlfile.
v$bh
This dynamic view has an entry for each block in the database buffer cache.
The column status can be:
* free
This block is not in use
* xcur
Block held exclusively by this instance
* scur
Block held in cache, shared with other instance
* cr
Block for consistent read
* read
Block being read from disk
* mrec
Block in media recovery mode
* irec
Block in instance (crash) recovery mode
v$buffer_pool
See buffer pools.
This view's column id can be joined with x$kcbwds.indx
See also x$kcbwbpd
v$buffer_pool_statistics
v$database
This view lets you access database information. For example, you can check (using log_mode) whether or not the database is in archivelog mode:
ADPDB>select log_mode from v$database;
LOG_MODE
------------
ARCHIVELOG
checkpoint_change# records the SCN of the last checkpoint.
switchover_status: can be used to determine if it is possible to perform a switchover operation Only available for physical standby databases. Can be:
* NOT ALLOWED,
* SESSIONS ACTIVE,
* SWITCHOVER PENDING,
* SWITCHOVER LATENT,
* TO PRIMARY,
* TO STANDBY or
* RECOVERY NEEDED.
See protection modes in data guard for the columns protection_mode and protection_level.
database_role determines if a database is a primary or a logical standby database or a physical standby database.
force_logging tells if a database is in force logging mode or not.
v$datafile
This view contains an entry for each datafile of the database.
This view can be used to find out which datafiles must be backed up in a cold backup: select name from v$datafile
v$datafile_header
Various information about datafile headers. For example, if you're interested in when the a file's last checkpoint was:
select name, checkpoint_change#, to_char(checkpoint_time, 'DD.MM.YYYY HH24:MI:SS') from v$datafile_header
v$dataguard_status
Shows error messages in a data guard environment.
v$db_object_cache
This view displays objects that are cached (pinned) in the library cache. See also dbms_shared_pool.
v$enqueue_stat
If there are a lot of enqueue waits "in" v$session_event or v$system_event, v$enqueue_stat allows to break down those enqueues in enqueue classes. For each such class, the gets, waits, failures and the cumulative sum of waited time can be found.
For a list of enqueue types, refer to enqueue types in x$ksqst.
The column cum_wait_time stems from x$ksqst.ksqstwtim.
v$eventmetric
This view is new in Oracle 10g and allows improved timing and statistics.
v$event_name
Contains a record for each wait event.
v$filemetric
This view is new in Oracle 10g and allows improved timing and statistics.
v$filestat
v$fixed_table
This view contains the name of all V$, X$ and GV$ tables. In oracle 8.1.7, there are 187 different v$ tables:
ORA81> select count(*) from v where name like 'V$%';
COUNT(*)
----------
185
If you want to know, which x$ tables there are, do a select name from v$fixed_table where name like 'X$%';
v$fixed_view_definition
Contains the defintion in its attribute view_definition for the views of v$fixed_table.
v$flash_recovery_area_usage
See also v$recovery_file_dest
v$instance
instance_role can be used to determine if an instance is an active instance (=primary instance) or a secondary instance (in a standby environment.
dbms_utility.db_version can be used to retrieve the same version as the field version in v$instance.
v$instance_recovery
Can, for example, be used to determine the optimal size of redo logs.
v$latch
Oracle collects statistics for the activity of all latches and stores these in this view. Gets is the number of successful willing to wait requests for a latch. Similarly, misses is how many times a process didn't successfully request a latch. Spin_gets: number of times a latch is obtained after spinning at least once. Sleeps indicates how many times a willing to wait process slept. Waiters_woken tells how often a sleeping process was 'disturbed'.
v$librarycache
v$lock
This view stores all information relating to locks in the database. The interesting columns in this view are sid (identifying the session holding or aquiring the lock), type, and the lmode/request pair.
Important possible values of type are TM (DML or Table Lock), TX (Transaction), MR (Media Recovery), ST (Disk Space Transaction).
Exactly one of the lmode, request pair is either 0 or 1 while the other indicates the lock mode. If lmode is not 0 or 1, then the session has aquired the lock, while it waits to aquire the lock if request is other than 0 or 1. The possible values for lmode and request are:
* 1: null,
* 2: Row Share (SS),
* 3: Row Exclusive (SX),
* 4: Share (S),
* 5: Share Row Exclusive (SSX) and
* 6: Exclusive(X)
If the lock type is TM, the column id1 is the object's id and the name of the object can then be queried like so: select name from sys.obj$ where obj# = id1
A lock type of JI indicates that a materialized view is being refreshed.
A more detailed example can be found here
See also x$kgllk.
v$locked_object
Who is locking what:
select
oracle_username
os_user_name,
locked_mode,
object_name,
object_type
from
v$locked_object a,dba_objects b
where
a.object_id = b.object_id
v$log
Contains information on each log group. See also online redo log.
Comman values for the status column are:
* UNUSED:
Oracle8 has never written to this group,
* CURRENT:
This is the active group.
* ACTIVE:
Oracle has written to this log before, it is needed for instance recovery.
The active log is the one with the current log sequence number
* INACTIVE:
Oracle has written to this log before; it is not needed for instance recovery.
v$logfile
This view can be queried to find the filenames, group numbers and states of redo log files. For example, to find all files of group 2, use select member from v$logfile where group# = 2
v$logmnr_contents
See dbms_logmnr.
v$log_history
This view contains an entry for each Log Switch that occured. The column first_time indicates the time of the first entry???
On physical standby databases, this view shows applied logs.
v$logstdby
Can be used to verify that archived redo logs are being applied to standby databases.
v$managed_standby
Monitors the progress of a standby database in managed recovery mode, more exactly, it displays information about the activities of log transport service and log apply service.
see here
select process, pid, status, client_process, group# "Stdby Redo Log Gr", block# from v$managed_standby;
client_process: the corresponding primary database process. If lgwr log transmission is chosen, one row should have client_process=LGWR. If ARCH transmission is chosen, one row should have ARCH.
v$mystat
This view records statistical data about the session that accesses it. Join statistic# with v$statname.
v$sesstat is also similar to v$sysstat, except that v$sysstat accumulates the statistics as soon as a session terminates.
See also recording statistics with oracle.
v$nls_parameters
The NLS parameters that are in effect for the session quering this view. The view NLS_SESSION_PARAMETERS is based on v$nls_parameters. See also v$nls_valid_values.
v$nls_valid_values
This view can be used to obtain valid values for NLS parameters such as
* supported character sets
* languages
* territories
* sorting orders
v$object_usage
v$object_usage gathers information about used (accessed) indexes when an index is monitored using alter index ... monitoring usage.
See On verifying if an index is used.
v$open_cursor
v$option
This view lets you see which options are installed in the server.
See also dba_registry.
v$parameter
Lists the name-value pairs of the init.ora file (or their default, if not in the init.ora). For example, if you need to know what your block size is:
select value from v$parameter where name = 'db_block_size'
The columns isses_modifiable and issys_modifiable can be used to determine if a parameter can be changed at session level using alter session or at system level using alter system. A parameter is modifiable at session level if isses_modifiable = 'TRUE'. A parameter is modifiable at system level if issys_modifiable = 'DEFERRED' or issys_modifiable = 'IMMEDIATE'. However, if a parameter is changed at system level if issys_modifiable = 'DEFERRED' it only affects sessions that are started after chaning the parameter. Additionally, the alter system set ... deferred option must be used.
There are also some undocumented (or hidden?) parameters.
v$pgastat
See also pga.
Thanks to Oleg who notified me of a typo (v$pgastat instead of v$pga_stat).
v$process
Join v$process's addr with v$session paddr.
The column traceid is equal to the value used in alter session set .
v$pwfile_users
Lists all users who have been granted sysdba or sysoper privileges. See adding user to a password file.
v$recover_file
Useful to find out which datafiles need recovery.
Join with v$datafile to see filenames instead of numbers....
v$recovery_file_dest
See also v$flash_recovery_area_usage
v$reserved_words
This view can be consulted if one is in doubt wheter a particular word is a reserved word (for example when writing PL/SQL Code or assigning a password to a user).
Until 10g, the view only consist of two columns: keyword and length. From 10gR2 onwards, it has also the columns reserved, res_type, res_attr, res_semi and duplicate. Each of these new columns can only be either 'Y' (meaning: yes) or 'N' (meaning: no)
See also reserved words in SQL and reserved words in PL/SQL.
v$resource_limit
v$rollname
The names of online rollback segments. This view's usn field can be joined with v$rollstat's usn field and with v$transaction's xidusn field.
v$transaction can be used to track undo by session.
v$rollstat
Statistics for rollback segements
v$session
The column audsid can be joined with sys_context('userenv','SESSIONID') to find out which session is the "own one". Alternatively, dbms_support.mysid can be used.
The fields module and action of v$session can be set with dbms_application_info.set_module. (See v$session_longops for an example.
The field client_info can be set with dbms_application_info.set_client_info
Join sid with v$sesstat if you want to get some statistical information for a particular sesssion.
A record in v$session contains sid and serial#. These numbers can be used kill a session (alter system kill session).
A client can set some information in client_info. For example, RMAN related sessions can be found with
.... where client_info like 'rman%';
What a session is waiting for can be queried with v$session_wait. However, with Oracle 10g, this is not nessessary anymore, as v$session_wait's information will be exposed within v$session as well.
See also sessions.
v$sessmetric
This view is new in Oracle 10g and allows improved timing and statistics.
v$session_event
This views is similar to v$system_event. However, it breaks it down to currently connected sessions.
v$session_event has also the column max_wait that shows the maximum time waited for a wait event.
v$session_longops
Use v$session_longops if you have a long running pl/sql procedure and want to give feedback on how far the procedure proceeded.
If the following Procedure is run, it will report its progress in v$session_longops. The Procedure will also set the module attribute in v$session which makes it possible to find the sid and serial# of the session.
create table f(g number);
create or replace procedure long_proc as
rindex pls_integer := dbms_application_info.set_session_longops_nohint;
slno pls_integer;
-- Name of task
op_name varchar2(64) := 'long_proc';
target pls_integer := 0; -- ie. The object being worked on
context pls_integer; -- Any info
sofar number; -- how far proceeded
totalwork number := 1000000; -- finished when sofar=totalwork
-- desc of target
target_desc varchar2(32) := 'A long running procedure';
units varchar2(32) := 'inserts'; -- unit of sofar and totalwork
begin
dbms_application_info.set_module('long_proc',null);
dbms_application_info.set_session_longops (
rindex,
slno);
for sofar in 0..totalwork loop
insert into f values (sofar);
if mod(sofar,1000) = 0 then
dbms_application_info.set_session_longops (
rindex,
slno,
op_name,
target,
context,
sofar,
totalwork,
target_desc,
units);
end if;
end loop;
end long_proc;
If the procedure long_proc is run, you can issue the following query to get feedback on its progress:
select time_remaining,sofar,elapsed_seconds
from v$session_longops l, v$session s
where l.sid=s.sid and l.serial# = s.serial# and s.module='long_proc'
v$session_wait
This views shows what wait event each session is waiting for, or what the last event was that it waited for.
In contrast, v$session_event lists the cumulative history of events waited for in a session.
The columns P1, P2 and P3 are parameters that are dependant on the event. With Oracle 10g, v$session_wait's information will be exposed within v$session as well.
Since 10g, Oracle displays the v$session_wait information also in the v$session view.
v$session_wait_history
This view is new in Oracle 10g and allows improved timing and statistics.
v$sesstat
This view is similar to v$mystat except that it shows cumulated statistics for all sessions.
Join sid with v$session and join statistic# with v$statname.
v$sesstat is also similar to v$sysstat, except that v$sysstat accumulates the statistics as soon as a session terminates.
v$sga
Shows how much memory the shared global area uses. Selecting * from v$sga is roughly the same as typing show sga in sql plus with the exeption that the latter also show the total.
v$sgastat
Showing free space in the sga:
select * from v$sgastat where name = 'free memory'
v$sga_dynamic_components
Information about SGA resize operations since startup.
This view can also be used to find out the granule size of SGA components.
v$sga_resize_ops
v$sort_usage
See temporary tablespaces
v$sort_segment
See Temporary Tablespaces
v$spparameter
Returns the values for the spfile.
v$sql
v$sql is similar to v$sqlarea, the main difference being that v$sql drills down to select * from x$kglob whereas v$sqlarea drills down to select sum from x$kglob. See also here.
v$sqlarea
Join v$sqlarea's address with v$session's sql_address.
Find the SQL-text of currently running SQL statements:
select sql_text from v$sqlarea where users_executing > 0;
The field version_count indicates how many versions an sql statement has.
v$sqltext
v$sql_plan
variable addr varchar2(20)
variable hash number
variable child number
exec :addr := '&sqladdr'; :hash := &hashvalue; :child := &childno;
select lpad(' ', 2*(level-1))||operation||' '||
decode(id, 0, 'Cost = '||position) "OPERATION",
options, object_name
from v$sql_plan
start with (address = :addr
and hash_value = :hash
and child_number = :child
and id=0 )
connect by prior id = parent_id
and prior address = address
and prior hash_value = hash_value
and prior child_number = child_number
order by id, position ;
In order to find valid values for sqladdr, hashvalue and childno, this SQL statement can be used:
select sql_text,address,hash_value,child_number from v$sql where users_executing > 0;
v$sql_text_with_newlines
This view can be used to construct the entire text for each session's actual SQL statement. Use the following statement to to that:
set serveroutput on size 1000000
declare
v_stmt varchar2(16000);
v_sql_text v$sqltext_with_newlines.sql_text%type;
v_sid v$session.sid%type;
begin
for r in (
select
sql_text,s.sid
from
v$sqltext_with_newlines t,
v$session s
where
s.sql_address=t.address
order by s.sid, piece) loop
v_sid := nvl(v_sid,r.sid);
if v_sid <> r.sid then
dbms_output.put_line(v_sid);
put_line(v_stmt,100);
v_sid := r.sid;
v_stmt := r.sql_text;
else
v_stmt := v_stmt || r.sql_text;
end if;
end loop;
dbms_output.put_line(v_sid);
dbms_output.put_line(v_stmt,100);
end;
/
Thanks to Sarmad Zafar who notified me of an error in this PL/SQL Block.
Note: the function put_line is found here and can be used to prevent ORU-10028.
v$sql_bind_data
Join cursor_num with cno of v$sql_cursor.
v$sql_bind_capture
New with Oracle 10g
This view captures bind variables for all sessions and is faster than setting 10046 on level 4.
v$sql_cursor
Join parent_handle with address of v$sql or v$sqlarea.
v$sql_workarea
v$sql_workarea can be joined with v$sqlarea on address and hash_value, and it can be joined with v$sql on address, hash_value and child_number.
v$standby_log
v$statname
Use this view to get decoded names for the statistic# field of v$mystat, v$sysstat and v$sesstat.
v$sysaux_occupants
v$sysaux_occupants doesn't exist in Oracle versions prior to Oracle 10g.
See occupants in the sysaux tablepsaces.
v$sysmetric
This view is new in Oracle 10g and allows improved timing and statistics.
v$sysmetric_history
This view is new in Oracle 10g and allows improved timing and statistics.
v$sysstat
v$sysstat is similar to v$sesstat. While v$sesstat displays statitics for the current session, v$sysstat displays the cumulated statitics since startup of the database.
For example, it is possible to find out the CPU time (name = 'CPU used by this session')
This view is (among others) used to calculate the Hit Ratio.
v$system_event
This view displays the count (total_waits) of all wait events since startup of the instance.
If timed_statistics is set to true, the sum of the wait times for all events are also displayed in the column time_waited.
The unit of time_waited is one hundreth of a second. Since 10g, an additional column (time_waited_micro) measures wait times in millionth of a second.
total_waits where event='buffer busy waits' is equal the sum of count in v$waitstat.
v$enqueue_stat can be used to break down waits on the enqueue wait event.
While this view totals all events in an instance, v$session_event breaks it down to all currently connected sessions.
v$undostat
undo tablespaces
v$tempfile
v$tempseg_usage
v$tempseg_usage is a public synonym for v$sort_usage.
v$tempstat
v$thread
The Oracle SID can be retrieved through select instance from v$thread
v$timer
This view has only one column (hsecs) which counts hundreths of seconds. Whenever it overflows four bytes, it starts again with 0.
v$transaction
Important fields of v$transaction are used_ublk and used_urec. They tell of how many blocks and records the undo for a transaction consists. In order to find out the name of the corresponding rollback segemnt, join the xidusn field with the usn field of v$rollname. This is demonstrated in
Transactions generate undo
v$timezone_names
See also timezones for some values of tzabbrev.
v$transportable_platform
Which platforms are supported for cross platform transportable tablespaces.
v$version
Use this view to find out what version you actually work on: select * from v$version;
BANNER
----------------------------------------------------------------
Oracle8i Enterprise Edition Release 8.1.7.0.0 - Production
PL/SQL Release 8.1.7.0.0 - Production
CORE 8.1.7.0.0 Production
TNS for 32-bit Windows: Version 8.1.7.0.0 - Production
NLSRTL Version 3.4.1.0.0 - Production
v$waitstat
total_waits where event='buffer busy waits' is equal the sum of count in v$system_event.
regards,
rajeshkumar
from the source
http://www.adp-gmbh.ch/ora/misc/dynamic_performance_views.html
v$archive_dest
Shows all archived redo log destinations. Use this view to find out to which place archived redo logs are copied: select dest_id,destination from v$archive_dest
These values correspond to the init parameter log_archive_dest_n.
v$archive_dest_status
This view allows to find status and errors for each of the defined
v$archived_log
Displays successfully archived redo logs.
shows received logs on a primary standby database.
v$archive_gap
Lists sequence numbers of the archived los that are known to be missing for each thread on a (physical?) standby database (highest gap only).
v$archive_processes
This view provides information on the archive processes. It can be used to find out if an ARCH process is active or not.
v$controlfile
Displays the location and status of each controlfile in the database.
v$controlfile_record_section
See sections in a controlfile.
v$bh
This dynamic view has an entry for each block in the database buffer cache.
The column status can be:
* free
This block is not in use
* xcur
Block held exclusively by this instance
* scur
Block held in cache, shared with other instance
* cr
Block for consistent read
* read
Block being read from disk
* mrec
Block in media recovery mode
* irec
Block in instance (crash) recovery mode
v$buffer_pool
See buffer pools.
This view's column id can be joined with x$kcbwds.indx
See also x$kcbwbpd
v$buffer_pool_statistics
v$database
This view lets you access database information. For example, you can check (using log_mode) whether or not the database is in archivelog mode:
ADPDB>select log_mode from v$database;
LOG_MODE
------------
ARCHIVELOG
checkpoint_change# records the SCN of the last checkpoint.
switchover_status: can be used to determine if it is possible to perform a switchover operation Only available for physical standby databases. Can be:
* NOT ALLOWED,
* SESSIONS ACTIVE,
* SWITCHOVER PENDING,
* SWITCHOVER LATENT,
* TO PRIMARY,
* TO STANDBY or
* RECOVERY NEEDED.
See protection modes in data guard for the columns protection_mode and protection_level.
database_role determines if a database is a primary or a logical standby database or a physical standby database.
force_logging tells if a database is in force logging mode or not.
v$datafile
This view contains an entry for each datafile of the database.
This view can be used to find out which datafiles must be backed up in a cold backup: select name from v$datafile
v$datafile_header
Various information about datafile headers. For example, if you're interested in when the a file's last checkpoint was:
select name, checkpoint_change#, to_char(checkpoint_time, 'DD.MM.YYYY HH24:MI:SS') from v$datafile_header
v$dataguard_status
Shows error messages in a data guard environment.
v$db_object_cache
This view displays objects that are cached (pinned) in the library cache. See also dbms_shared_pool.
v$enqueue_stat
If there are a lot of enqueue waits "in" v$session_event or v$system_event, v$enqueue_stat allows to break down those enqueues in enqueue classes. For each such class, the gets, waits, failures and the cumulative sum of waited time can be found.
For a list of enqueue types, refer to enqueue types in x$ksqst.
The column cum_wait_time stems from x$ksqst.ksqstwtim.
v$eventmetric
This view is new in Oracle 10g and allows improved timing and statistics.
v$event_name
Contains a record for each wait event.
v$filemetric
This view is new in Oracle 10g and allows improved timing and statistics.
v$filestat
v$fixed_table
This view contains the name of all V$, X$ and GV$ tables. In oracle 8.1.7, there are 187 different v$ tables:
ORA81> select count(*) from v where name like 'V$%';
COUNT(*)
----------
185
If you want to know, which x$ tables there are, do a select name from v$fixed_table where name like 'X$%';
v$fixed_view_definition
Contains the defintion in its attribute view_definition for the views of v$fixed_table.
v$flash_recovery_area_usage
See also v$recovery_file_dest
v$instance
instance_role can be used to determine if an instance is an active instance (=primary instance) or a secondary instance (in a standby environment.
dbms_utility.db_version can be used to retrieve the same version as the field version in v$instance.
v$instance_recovery
Can, for example, be used to determine the optimal size of redo logs.
v$latch
Oracle collects statistics for the activity of all latches and stores these in this view. Gets is the number of successful willing to wait requests for a latch. Similarly, misses is how many times a process didn't successfully request a latch. Spin_gets: number of times a latch is obtained after spinning at least once. Sleeps indicates how many times a willing to wait process slept. Waiters_woken tells how often a sleeping process was 'disturbed'.
v$librarycache
v$lock
This view stores all information relating to locks in the database. The interesting columns in this view are sid (identifying the session holding or aquiring the lock), type, and the lmode/request pair.
Important possible values of type are TM (DML or Table Lock), TX (Transaction), MR (Media Recovery), ST (Disk Space Transaction).
Exactly one of the lmode, request pair is either 0 or 1 while the other indicates the lock mode. If lmode is not 0 or 1, then the session has aquired the lock, while it waits to aquire the lock if request is other than 0 or 1. The possible values for lmode and request are:
* 1: null,
* 2: Row Share (SS),
* 3: Row Exclusive (SX),
* 4: Share (S),
* 5: Share Row Exclusive (SSX) and
* 6: Exclusive(X)
If the lock type is TM, the column id1 is the object's id and the name of the object can then be queried like so: select name from sys.obj$ where obj# = id1
A lock type of JI indicates that a materialized view is being refreshed.
A more detailed example can be found here
See also x$kgllk.
v$locked_object
Who is locking what:
select
oracle_username
os_user_name,
locked_mode,
object_name,
object_type
from
v$locked_object a,dba_objects b
where
a.object_id = b.object_id
v$log
Contains information on each log group. See also online redo log.
Comman values for the status column are:
* UNUSED:
Oracle8 has never written to this group,
* CURRENT:
This is the active group.
* ACTIVE:
Oracle has written to this log before, it is needed for instance recovery.
The active log is the one with the current log sequence number
* INACTIVE:
Oracle has written to this log before; it is not needed for instance recovery.
v$logfile
This view can be queried to find the filenames, group numbers and states of redo log files. For example, to find all files of group 2, use select member from v$logfile where group# = 2
v$logmnr_contents
See dbms_logmnr.
v$log_history
This view contains an entry for each Log Switch that occured. The column first_time indicates the time of the first entry???
On physical standby databases, this view shows applied logs.
v$logstdby
Can be used to verify that archived redo logs are being applied to standby databases.
v$managed_standby
Monitors the progress of a standby database in managed recovery mode, more exactly, it displays information about the activities of log transport service and log apply service.
see here
select process, pid, status, client_process, group# "Stdby Redo Log Gr", block# from v$managed_standby;
client_process: the corresponding primary database process. If lgwr log transmission is chosen, one row should have client_process=LGWR. If ARCH transmission is chosen, one row should have ARCH.
v$mystat
This view records statistical data about the session that accesses it. Join statistic# with v$statname.
v$sesstat is also similar to v$sysstat, except that v$sysstat accumulates the statistics as soon as a session terminates.
See also recording statistics with oracle.
v$nls_parameters
The NLS parameters that are in effect for the session quering this view. The view NLS_SESSION_PARAMETERS is based on v$nls_parameters. See also v$nls_valid_values.
v$nls_valid_values
This view can be used to obtain valid values for NLS parameters such as
* supported character sets
* languages
* territories
* sorting orders
v$object_usage
v$object_usage gathers information about used (accessed) indexes when an index is monitored using alter index ... monitoring usage.
See On verifying if an index is used.
v$open_cursor
v$option
This view lets you see which options are installed in the server.
See also dba_registry.
v$parameter
Lists the name-value pairs of the init.ora file (or their default, if not in the init.ora). For example, if you need to know what your block size is:
select value from v$parameter where name = 'db_block_size'
The columns isses_modifiable and issys_modifiable can be used to determine if a parameter can be changed at session level using alter session or at system level using alter system. A parameter is modifiable at session level if isses_modifiable = 'TRUE'. A parameter is modifiable at system level if issys_modifiable = 'DEFERRED' or issys_modifiable = 'IMMEDIATE'. However, if a parameter is changed at system level if issys_modifiable = 'DEFERRED' it only affects sessions that are started after chaning the parameter. Additionally, the alter system set ... deferred option must be used.
There are also some undocumented (or hidden?) parameters.
v$pgastat
See also pga.
Thanks to Oleg who notified me of a typo (v$pgastat instead of v$pga_stat).
v$process
Join v$process's addr with v$session paddr.
The column traceid is equal to the value used in alter session set .
v$pwfile_users
Lists all users who have been granted sysdba or sysoper privileges. See adding user to a password file.
v$recover_file
Useful to find out which datafiles need recovery.
Join with v$datafile to see filenames instead of numbers....
v$recovery_file_dest
See also v$flash_recovery_area_usage
v$reserved_words
This view can be consulted if one is in doubt wheter a particular word is a reserved word (for example when writing PL/SQL Code or assigning a password to a user).
Until 10g, the view only consist of two columns: keyword and length. From 10gR2 onwards, it has also the columns reserved, res_type, res_attr, res_semi and duplicate. Each of these new columns can only be either 'Y' (meaning: yes) or 'N' (meaning: no)
See also reserved words in SQL and reserved words in PL/SQL.
v$resource_limit
v$rollname
The names of online rollback segments. This view's usn field can be joined with v$rollstat's usn field and with v$transaction's xidusn field.
v$transaction can be used to track undo by session.
v$rollstat
Statistics for rollback segements
v$session
The column audsid can be joined with sys_context('userenv','SESSIONID') to find out which session is the "own one". Alternatively, dbms_support.mysid can be used.
The fields module and action of v$session can be set with dbms_application_info.set_module. (See v$session_longops for an example.
The field client_info can be set with dbms_application_info.set_client_info
Join sid with v$sesstat if you want to get some statistical information for a particular sesssion.
A record in v$session contains sid and serial#. These numbers can be used kill a session (alter system kill session).
A client can set some information in client_info. For example, RMAN related sessions can be found with
.... where client_info like 'rman%';
What a session is waiting for can be queried with v$session_wait. However, with Oracle 10g, this is not nessessary anymore, as v$session_wait's information will be exposed within v$session as well.
See also sessions.
v$sessmetric
This view is new in Oracle 10g and allows improved timing and statistics.
v$session_event
This views is similar to v$system_event. However, it breaks it down to currently connected sessions.
v$session_event has also the column max_wait that shows the maximum time waited for a wait event.
v$session_longops
Use v$session_longops if you have a long running pl/sql procedure and want to give feedback on how far the procedure proceeded.
If the following Procedure is run, it will report its progress in v$session_longops. The Procedure will also set the module attribute in v$session which makes it possible to find the sid and serial# of the session.
create table f(g number);
create or replace procedure long_proc as
rindex pls_integer := dbms_application_info.set_session_longops_nohint;
slno pls_integer;
-- Name of task
op_name varchar2(64) := 'long_proc';
target pls_integer := 0; -- ie. The object being worked on
context pls_integer; -- Any info
sofar number; -- how far proceeded
totalwork number := 1000000; -- finished when sofar=totalwork
-- desc of target
target_desc varchar2(32) := 'A long running procedure';
units varchar2(32) := 'inserts'; -- unit of sofar and totalwork
begin
dbms_application_info.set_module('long_proc',null);
dbms_application_info.set_session_longops (
rindex,
slno);
for sofar in 0..totalwork loop
insert into f values (sofar);
if mod(sofar,1000) = 0 then
dbms_application_info.set_session_longops (
rindex,
slno,
op_name,
target,
context,
sofar,
totalwork,
target_desc,
units);
end if;
end loop;
end long_proc;
If the procedure long_proc is run, you can issue the following query to get feedback on its progress:
select time_remaining,sofar,elapsed_seconds
from v$session_longops l, v$session s
where l.sid=s.sid and l.serial# = s.serial# and s.module='long_proc'
v$session_wait
This views shows what wait event each session is waiting for, or what the last event was that it waited for.
In contrast, v$session_event lists the cumulative history of events waited for in a session.
The columns P1, P2 and P3 are parameters that are dependant on the event. With Oracle 10g, v$session_wait's information will be exposed within v$session as well.
Since 10g, Oracle displays the v$session_wait information also in the v$session view.
v$session_wait_history
This view is new in Oracle 10g and allows improved timing and statistics.
v$sesstat
This view is similar to v$mystat except that it shows cumulated statistics for all sessions.
Join sid with v$session and join statistic# with v$statname.
v$sesstat is also similar to v$sysstat, except that v$sysstat accumulates the statistics as soon as a session terminates.
v$sga
Shows how much memory the shared global area uses. Selecting * from v$sga is roughly the same as typing show sga in sql plus with the exeption that the latter also show the total.
v$sgastat
Showing free space in the sga:
select * from v$sgastat where name = 'free memory'
v$sga_dynamic_components
Information about SGA resize operations since startup.
This view can also be used to find out the granule size of SGA components.
v$sga_resize_ops
v$sort_usage
See temporary tablespaces
v$sort_segment
See Temporary Tablespaces
v$spparameter
Returns the values for the spfile.
v$sql
v$sql is similar to v$sqlarea, the main difference being that v$sql drills down to select * from x$kglob whereas v$sqlarea drills down to select sum from x$kglob. See also here.
v$sqlarea
Join v$sqlarea's address with v$session's sql_address.
Find the SQL-text of currently running SQL statements:
select sql_text from v$sqlarea where users_executing > 0;
The field version_count indicates how many versions an sql statement has.
v$sqltext
v$sql_plan
variable addr varchar2(20)
variable hash number
variable child number
exec :addr := '&sqladdr'; :hash := &hashvalue; :child := &childno;
select lpad(' ', 2*(level-1))||operation||' '||
decode(id, 0, 'Cost = '||position) "OPERATION",
options, object_name
from v$sql_plan
start with (address = :addr
and hash_value = :hash
and child_number = :child
and id=0 )
connect by prior id = parent_id
and prior address = address
and prior hash_value = hash_value
and prior child_number = child_number
order by id, position ;
In order to find valid values for sqladdr, hashvalue and childno, this SQL statement can be used:
select sql_text,address,hash_value,child_number from v$sql where users_executing > 0;
v$sql_text_with_newlines
This view can be used to construct the entire text for each session's actual SQL statement. Use the following statement to to that:
set serveroutput on size 1000000
declare
v_stmt varchar2(16000);
v_sql_text v$sqltext_with_newlines.sql_text%type;
v_sid v$session.sid%type;
begin
for r in (
select
sql_text,s.sid
from
v$sqltext_with_newlines t,
v$session s
where
s.sql_address=t.address
order by s.sid, piece) loop
v_sid := nvl(v_sid,r.sid);
if v_sid <> r.sid then
dbms_output.put_line(v_sid);
put_line(v_stmt,100);
v_sid := r.sid;
v_stmt := r.sql_text;
else
v_stmt := v_stmt || r.sql_text;
end if;
end loop;
dbms_output.put_line(v_sid);
dbms_output.put_line(v_stmt,100);
end;
/
Thanks to Sarmad Zafar who notified me of an error in this PL/SQL Block.
Note: the function put_line is found here and can be used to prevent ORU-10028.
v$sql_bind_data
Join cursor_num with cno of v$sql_cursor.
v$sql_bind_capture
New with Oracle 10g
This view captures bind variables for all sessions and is faster than setting 10046 on level 4.
v$sql_cursor
Join parent_handle with address of v$sql or v$sqlarea.
v$sql_workarea
v$sql_workarea can be joined with v$sqlarea on address and hash_value, and it can be joined with v$sql on address, hash_value and child_number.
v$standby_log
v$statname
Use this view to get decoded names for the statistic# field of v$mystat, v$sysstat and v$sesstat.
v$sysaux_occupants
v$sysaux_occupants doesn't exist in Oracle versions prior to Oracle 10g.
See occupants in the sysaux tablepsaces.
v$sysmetric
This view is new in Oracle 10g and allows improved timing and statistics.
v$sysmetric_history
This view is new in Oracle 10g and allows improved timing and statistics.
v$sysstat
v$sysstat is similar to v$sesstat. While v$sesstat displays statitics for the current session, v$sysstat displays the cumulated statitics since startup of the database.
For example, it is possible to find out the CPU time (name = 'CPU used by this session')
This view is (among others) used to calculate the Hit Ratio.
v$system_event
This view displays the count (total_waits) of all wait events since startup of the instance.
If timed_statistics is set to true, the sum of the wait times for all events are also displayed in the column time_waited.
The unit of time_waited is one hundreth of a second. Since 10g, an additional column (time_waited_micro) measures wait times in millionth of a second.
total_waits where event='buffer busy waits' is equal the sum of count in v$waitstat.
v$enqueue_stat can be used to break down waits on the enqueue wait event.
While this view totals all events in an instance, v$session_event breaks it down to all currently connected sessions.
v$undostat
undo tablespaces
v$tempfile
v$tempseg_usage
v$tempseg_usage is a public synonym for v$sort_usage.
v$tempstat
v$thread
The Oracle SID can be retrieved through select instance from v$thread
v$timer
This view has only one column (hsecs) which counts hundreths of seconds. Whenever it overflows four bytes, it starts again with 0.
v$transaction
Important fields of v$transaction are used_ublk and used_urec. They tell of how many blocks and records the undo for a transaction consists. In order to find out the name of the corresponding rollback segemnt, join the xidusn field with the usn field of v$rollname. This is demonstrated in
Transactions generate undo
v$timezone_names
See also timezones for some values of tzabbrev.
v$transportable_platform
Which platforms are supported for cross platform transportable tablespaces.
v$version
Use this view to find out what version you actually work on: select * from v$version;
BANNER
----------------------------------------------------------------
Oracle8i Enterprise Edition Release 8.1.7.0.0 - Production
PL/SQL Release 8.1.7.0.0 - Production
CORE 8.1.7.0.0 Production
TNS for 32-bit Windows: Version 8.1.7.0.0 - Production
NLSRTL Version 3.4.1.0.0 - Production
v$waitstat
total_waits where event='buffer busy waits' is equal the sum of count in v$system_event.
regards,
rajeshkumar
from the source
http://www.adp-gmbh.ch/ora/misc/dynamic_performance_views.html
Thursday, November 12, 2009
Logical vs. Physical Standby databases
Logical vs. Physical Standby databases
Submitted By Rama Subramoniam on www.orafaq.com
A Quick Primer
Standby databases, in a nutshell, acts as a failover for our mission critical production databases. When production database crashes, applications can quickly switchover to the stand by databases.
Oracle provides two types of standby databases:
1. Physical Standby Database
Standby database is called “physical” if the physical structure of stand by exactly matches with stand by structure. Archived redo log transferred from primary database will be directly applied to the stand by database.
2. Logical Standby Database
Stand by database is called “logical”, the physical structure of both
databases do not match and from the archived redo log we create SQL statements then these statements will be applied to stand by database.
Administer Standby Databases
I would say there are three ways we can administer standby database.
1. SQL/Shell Scripts
This is the basic and simple method to create standby database, monitor the log transport and log apply services.
2. DGMGRL
DGMGRL stands for Data Guard Line Mode, a tool provided by oracle to administer standby database.
How it works?
In any typical standby db environment there will be only one primary database and one or more standby databases. With dgmgrl, we need to create one object for primary db called “Configuration” and for each stand by database we create one object alled“site”.Theseobjects“Configuration” and “sites” are interrelated.
Things to remember when using DGMGRL
* You can not create standby databases thru dgmgrl.You can only use this tool to monitor or switch over dbs.
* You need to have “sp file” created for all primary/stand by dbs.
* From dgmgrl, you need to always connect with primary db to perform any activities otherwise its not going work.
* The parameter dg_broker_start must be set to TRUE
3. OEM
We can use Oracle Enterprise Manager (OEM) to administer both physical and logical standby databases.
How to Create Physical Standby Database
Before you go thru the steps listed below in our example I call primary database as “TEST” and standby database as “TEST_S1”.But keep in mind when you create standby database the environment variable ORACLE_SID is going to be same as primary db name (TEST in our case).
1) Ensure the Primary database is in ARCHIVELOG mode:
SQL> archive log list
Database log mode No Archive Mode
Automatic archival Disabled
Archive destination /export/home/oracle/temp/oracle/arch
Oldest online log sequence 7
Current log sequence 9
SQL> alter database close;
Database altered.
SQL> alter database archivelog;
Database altered.
SQL> shutdown immediate
ORA-01109: database not open
Database dismounted.
ORACLE instance shut down.
Modify the Primary database init.ora so that log_archive_start=true and restart the instance. Verify that database is in archive log mode and that automatic archiving is enabled.
SQL> archive log list
Database log mode Archive Mode
Automatic archival Enabled
Archive destination /export/home/oracle/temp/oracle/arch
Oldest online log sequence 7
Next log sequence to archive 9
Current log sequence 9
2) Create a backup of the Primary database
You can use an existing backup of the Primary database as long as you have the archive logs that have been generated since that backup. You may also take a hot backup as long as you have all archive logs through the end of the backup of the last table space. To create a cold backup do the following:
SQL> select name from v$datafile;
NAME
----------------------------------------------------------------
/export/home/oracle/temp/oracle/data/sys.dbf
SQL> shutdown immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> exit
Create a backup of all data files and online redo logs using an OS command or utility. A backup of the online redo logs is necessary to facilitate switchover.
Once complete startup the instance:
SQL> startup
ORACLE instance started.
Total System Global Area 80512156 bytes
Fixed Size 279708 bytes
Variable Size 71303168 bytes
Database Buffers 8388608 bytes
Redo Buffers 540672 bytes
Database mounted.
Database opened.
3) Connect to the primary database and create the standby control file:
SQL> alter database create standby control file as
'/export/home/oracle/temp/oracle/data/backup/standby.ctl';
Database altered.
4) Copy files to the Standby host
Copy the backup data files, standby control file, all available archived redo logs, and online redo logs from the primary site to the standby site. Copying of the online redo logs is necessary to facilitate switchover. If the standby is on a separate site with the same directory structure as the primary database then you can use the same path names for the standby files as the primary files. In this way, you do not have to rename the primary data files in the standby control file. If the standby is on the same site as the primary database, or the standby database is on a separate site with a different directory structure the you must rename the primary data files in the standby control file after copying them to the standby site. This can be done using the db_file_name_convert and log_file_name_convert parameters or by manually using the alert database statements.
5) Set the initialization parameters for the primary database
It is suggested that you maintain two init.ora files on both the primary and the standby databases. This allows you to facilitate role reversal during switchover operations more easily.
For primary database ========
1. initTEST.ora
2. switch_to_stdby_initTEST
For Standby database =======
1. initTEST_s1.ora
2. switch_to_primary_initTEST
On primary initTEST.ora file add the following lines:
log_archive_dest_1='LOCATION=/export/home/oracle/temp/oracle/arch’
log_archive_dest_2='SERVICE=TEST_s1 reopen=60'
log_archive_dest_state_1=enable
log_archive_dest_state_2=enable
log_archive_format=%t_%s.dbf
log_archive_start=true
remote_archive_enable=true
Create the standby initialization parameter file and set the parameters for the standby database. Depending on your configuration, you may need to set filename conversion parameters.
Standby init.ora on Primary host:
log_archive_dest_1='LOCATION=/export/home/oracle/temp/oracle/arch'
log_archive_dest_state_1=enable
log_archive_format=%t_%s.dbf
log_archive_start=true
standby_archive_dest=/export/home/oracle/temp/oracle/arch
standby_file_management=auto
fal_server=TEST_s1
fal_client=TEST
remote_arhive_enable=true
NOTE: In the above example, db_file_name_convert and log_file_name_convert are not needed as the directory structure on the two hosts are the same. If the directory structure is not the same then setting of these parameters is recommended.
6) Configure networking components
On the Primary host create a net service name that the Primary database can use to connect to the Standby database. On the primary host creates a net service name that Standby, when running on the Primary host, can use to connect to the Primary, when it is running on the Standby host. Example from
Primary’s host tnsnames.ora:
TEST =
(DESCRIPTION =
(ADDRESS= (PROTOCOL= TCP) (Host= 172.20.69.83) (Port= 1523))
(CONNECT_DATA = (SID= TEST))
)
TEST_s1 =
(DESCRIPTION =
(ADDRESS= (PROTOCOL= TCP) (Host= 172.20.89.7) (Port= 1530))
(CONNECT_DATA = (SID= TEST))
)
The above two net service names must exist in the Standby hosts tnsnames.ora also. You must also configure a listener on the standby database. If you plan to manage this standby database using the Data Guard broker, you must configure the listener to use the TCP/IP protocol and statically register the standby database service using its SID.
7) Start up and mount the stand by database
oracle@hasunclu2:/export/home/oracle/temp/oracle> sqlplus "/ as sysdba"
SQL*Plus: Release 9.0.1.0.0 - Production on Thu Mar 14 18:00:57 2002 (c) Copyright 2001 Oracle Corporation. All rights reserved.
Connected to an idle instance.
SQL> startup nomount pfile=?/dbs/initTEST_s1.ora
ORACLE instance started.
Total System Global Area 80512156 bytes
Fixed Size 279708 bytes
Variable Size 71303168 bytes
Database Buffers 8388608 bytes
Redo Buffers 540672 bytes
SQL> alter database mount standby database;
Database altered.
SQL>
8) Create standby redo log files, if necessary
Standby redo logs are necessary for the higher protection levels such as Guaranteed, Instant, and Rapid. In these protection modes LGWR from the Primary host writes transactions directly to the standby redo logs. This enables no data loss solutions and reduces the amount of data loss in the event of failure. Standby redo logs are not necessary if you are using the delayed protection mode.
If you configure standby redo on the standby then you should also configure standby redo logs on the primary database. Even though the standby redo logs are not used when the database is running in the primary role, configuring the standby redo logs on the primary database is recommended in preparation for an eventual switchover operation.
Standby redo logs must be archived before the data can be applied to the standby database. The standby archival operation occurs automatically, even if the standby database is not in ARCHIVELOG mode. However, the archive process must be started on the standby database. Note that the use of the archiver process (ARCn) is a requirement for selection of a standby redo log.
You must have the same number of standby redo logs on the standby as you have online redo logs on production. They must also be exactly the same size.
The following syntax is used to create standby redo logs:
SQL> alter database add standby log file
'/export/home/oracle/temp/oracle/data/srl_1.dbf' size 20m;
Database altered.
SQL> alter database add standby log file
2 '/export/home/oracle/temp/oracle/data/srl_2.dbf' size 20m;
Database altered.
SQL> alter database add standby log file
2 ‘/export/home/oracle/temp/oracle/data/srl_3.dbf' size 20m;
Database altered.
SQL>
9) Copy database files
Manually change the names of the primary data files and redo logs in the standby control file for all files not automatically renamed using DB_FILE_NAME_CONVERT and LOG_FILE_NAME_CONVERT as noted in step 5.Datafile names can be changed on the standby at a mounted state with the following syntax:
SQL> alter database rename file
'/export/home/oracle/temp/oracle/data/sys.dbf'
to
'/export/home/oracle/temp/oracle/data2/sys.dbf';
10) Restart the listeners
On the primary database, and start the listener on the standby database so that changes made to the listener.ora can be implemented.
11) Activate parameter changes
Manually enable initialization parameter changes on the primary database so that it can initiate archiving to the standby site.
At runtime, the LOG_ARCHIVE_DEST_n initialization parameter can be changed using ALTER SYSTEM and ALTER SESSION statements. Activate the changes made to these parameters by either bouncing the instance or activating via alter system.
For example:
SQL> alter system set log_archive_dest_2='SERVICE=TEST_s1 reopen=60';
System altered.
12) Verify Auto Archive
On the Primary database switch a log and verify that it has been shipped properly using the v$archive_dest view.
SQL> alter system switch logfile;
System altered.
SQL> select status, error from v$archive_dest where dest_id=2;
STATUS ERROR
--------- ------------------------------------------------------
VALID
SQL>
13) Put Standby database in managed standby database
SQL> recover managed standby database disconnect;
Media recovery complete.
SQL> exit
14)Apply redo logs in the standby database
Remember archived logs will be transferred to stand by database. But we need to apply the archived logs to standby database. We can apply these archived logs either thru SQL or data guard command line tool (DGMGRL)
Let us see how we can apply thru SQL.
Go to standby database environment:
SQL> startup nomount pfile=initTEST_s1.ora
SQL> alter database mount standby database;
SQL> recover managed standby database disconnect;
Warning!!!After executing the above statement you will get the sql prompt. But that does not mean the recovery is complete. This statement will kick off “Disaster Recovery Service”.
SQL> recover managed standby database cancel;
The above statement will complete media recovery. Now all archive redo logs applied to standby database.
15) Switchover databases
In real time environment, if primary database is crashed or unavailable for some reason you need to make standby database as primary database.
• Switchover Standby to Primary
In order to do switchover standby have to be in mount state.
SQL> alter database commit to switch over to primary;
Sometimes, this command will ask to do media recovery on stand by instance. Apply logs as mentioned above and rerun the command.
SQL> shutdown immediate;
SQL> startup pfile=switch_to_primary_initTEST.ora
• Switchover Primary to Standby
SQL>alter database commit to switch over to standby;
SQL> shutdown immediate;
SQL> startup pfile= switch_to_stdby_initTEST.ora
How to Create Logical Standby Database
Now, let us talk about how we can create one logical standby database and administer logical standby database.
Before we create logical database perform the following checks to make sure the primary database qualify to have logical standby database.
• Determine whether primary database contains data types like LONG, NCLOB, LONG RAW, BFILE those are not supported by standby database.
• Ensure that the tables in primary database can be uniquely identified.
• Ensure that the primary database is in ARCHIVELOG mode and that archiving is enabled.
• Ensure supplemental logging is enabled on the primary database. To see whether supplemental logging is enabled, start a SQL session and query the V$DATABASE fixed view. For example, enter:
SQL> SELECT SUPPLEMENTAL_LOG_DATA_PK, SUPPLEMENTAL_LOG_DATA_UI
FROM V$DATABASE;
SUP SUP
--- ---
YES YES
If supplemental logging is not enabled, execute the following statements:
SQL> ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (PRIMARY KEY, UNIQUE INDEX) COLUMNS;
SQL> ALTER SYSTEM SWITCH LOGFILE;
• Ensure LOG_PARALLELISM init.ora parameter is set to 1 (default value).If you plan to be performing switchover operations with the logical standby then you must create an alternate tablespace in the primary database for logical standby system tables. Use the DBMS_LOGMNR_D.SET_TABLESPACE procedure to move the tables into the new tablespace. For example:
SQL> EXECUTE LOGMNR_D.SET_TABLESPACE
'logical_tblsp');
Steps to create Logical Standby Database
1. On primary database, perform cold backup.
2. Bring the primary database to mount state to create backup of control file.
3. Open the primary database and build the log miner dictionary.
SQL> ALTER system enable restricted session;
SQL> ALTER DATABASE OPEN;
SQL> EXECUTE DBMS_LOGSTDBY.BUILD;
4. Archive the current online redo log and disable the restricted session.
5. Identify the archived redo log that contains the log miner dictionary
SQL> SELECT NAME FROM V$ARCHIVED_LOG WHERE DICTIONARY_BEGIN='YES'
AND STANDBY_DEST='NO';
6. . Copy all these files with init parameter file to the stand by database.
7. On standby system, modify the copied primary init file to support the logical standby feature. Some parameters affected are control_files,standby_archive_dest,parallel_max_servers,instance_name.
8. Start and mount the standby database in exclusive mode.
9. Turn on the database guard.
ALTER DATABASE GUARD ALL;
10. Open the logical standby followed by a shutdown immediate or normal.
SQL> ALTER DATABASE OPEN RESETLOGS;
SQL> SHUTDOWN IMMEDIATE;
11. Open the logical standby database in exclusive mode.
12. Create temporary table space for the standby database.
13. On logical standby database, register the archived log identified in step 5 and run the following command.
SQL> ALTER DATABASE REGISTER LOGICAL LOGFILE
'/u01/oradata/stby/arch/arc1_28.arc';
14. Run the following ALTER DATABASE statement and include the INITIAL keyword to begin SQL apply operations for the first time on the logical standby.
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY INITIAL;
15. Configure listener on the standby database.
16. Once listeners running on both primary and standby databases run the following command.
ALTER SYSTEM RESGITER;
17. Create tns names entry for primary database in standby host. Similarly, create tns names entry for standby database in primary host.
18. Enable archiving in the logical standby database.
19. Start archive the current online redo log file. Verify that the remote archiving succeeded by running the following select statement.
SQL> SELECT STATUS, ERROR FROM V$ARCHIVE_DEST;
20. Verifying archived redo logs are being applied. To verify that the archived redo logs are being applied, query the V$LOGSTDBY view. This view provides information about the processes that are reading redo log information and applying it to the logical standby databases. You can also query the DBA_LOGSTDBY_PROGRESS view to find out the progress of SQL apply operations. The V$LOGSTDBY_STATS view shows the state of the coordinator process and information about the SQL transactions that have been applied to the logical standby database.
Logical or Physical, What is your Choice?
You ask you DBA to implement “stand by “database for your production database. Guess what? You will get “physical standby “database implemented for your production database. Because implementing physical standby database would be first choice for many DBAs as most of us would not realize the benefits we get from having logical standby database.
Let us take close look at the major bottleneck with physical stand by database.
We need to keep the physical standby database in “recovery mode” in order to apply the received archive logs from the primary database. We can open “physical stand by database to “read only” and make it available to the applications users (Only select is allowed during this period).Once the database is opened in “Read only” mode then we can not apply redo logs received from primary database.
We do not see such issues with logical standby database. We can open up the database in normal mode and make it available to the users. At the same time, we can apply archived logs received from primary database.
Real World Scenario
One of my clients was facing critical performance issue with their primary database. The primary database needed to support pretty large user community for the OLTP system and pretty large “Reporting Group”. The database could not cope up with these two large user groups. So I have configured “logical stand by” database for the primary database and I have opened up the database available to the reporting users group. Now the database load is kind of distributed between primary and standby database.
Conclusion
I will hazard a guess that you and many users now have a newfound respect for standby databases. In future, if you need to create standby databases ask yourself the following questions.
• Do I need just one failover database? Then you can choose physical standby database.
• Do I need failover database? Also I need to see whether I can make use of this failover database rather than sitting idle on the server. Then choose logical standby database.
Submitted By Rama Subramoniam on www.orafaq.com
A Quick Primer
Standby databases, in a nutshell, acts as a failover for our mission critical production databases. When production database crashes, applications can quickly switchover to the stand by databases.
Oracle provides two types of standby databases:
1. Physical Standby Database
Standby database is called “physical” if the physical structure of stand by exactly matches with stand by structure. Archived redo log transferred from primary database will be directly applied to the stand by database.
2. Logical Standby Database
Stand by database is called “logical”, the physical structure of both
databases do not match and from the archived redo log we create SQL statements then these statements will be applied to stand by database.
Administer Standby Databases
I would say there are three ways we can administer standby database.
1. SQL/Shell Scripts
This is the basic and simple method to create standby database, monitor the log transport and log apply services.
2. DGMGRL
DGMGRL stands for Data Guard Line Mode, a tool provided by oracle to administer standby database.
How it works?
In any typical standby db environment there will be only one primary database and one or more standby databases. With dgmgrl, we need to create one object for primary db called “Configuration” and for each stand by database we create one object alled“site”.Theseobjects“Configuration” and “sites” are interrelated.
Things to remember when using DGMGRL
* You can not create standby databases thru dgmgrl.You can only use this tool to monitor or switch over dbs.
* You need to have “sp file” created for all primary/stand by dbs.
* From dgmgrl, you need to always connect with primary db to perform any activities otherwise its not going work.
* The parameter dg_broker_start must be set to TRUE
3. OEM
We can use Oracle Enterprise Manager (OEM) to administer both physical and logical standby databases.
How to Create Physical Standby Database
Before you go thru the steps listed below in our example I call primary database as “TEST” and standby database as “TEST_S1”.But keep in mind when you create standby database the environment variable ORACLE_SID is going to be same as primary db name (TEST in our case).
1) Ensure the Primary database is in ARCHIVELOG mode:
SQL> archive log list
Database log mode No Archive Mode
Automatic archival Disabled
Archive destination /export/home/oracle/temp/oracle/arch
Oldest online log sequence 7
Current log sequence 9
SQL> alter database close;
Database altered.
SQL> alter database archivelog;
Database altered.
SQL> shutdown immediate
ORA-01109: database not open
Database dismounted.
ORACLE instance shut down.
Modify the Primary database init.ora so that log_archive_start=true and restart the instance. Verify that database is in archive log mode and that automatic archiving is enabled.
SQL> archive log list
Database log mode Archive Mode
Automatic archival Enabled
Archive destination /export/home/oracle/temp/oracle/arch
Oldest online log sequence 7
Next log sequence to archive 9
Current log sequence 9
2) Create a backup of the Primary database
You can use an existing backup of the Primary database as long as you have the archive logs that have been generated since that backup. You may also take a hot backup as long as you have all archive logs through the end of the backup of the last table space. To create a cold backup do the following:
SQL> select name from v$datafile;
NAME
----------------------------------------------------------------
/export/home/oracle/temp/oracle/data/sys.dbf
SQL> shutdown immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> exit
Create a backup of all data files and online redo logs using an OS command or utility. A backup of the online redo logs is necessary to facilitate switchover.
Once complete startup the instance:
SQL> startup
ORACLE instance started.
Total System Global Area 80512156 bytes
Fixed Size 279708 bytes
Variable Size 71303168 bytes
Database Buffers 8388608 bytes
Redo Buffers 540672 bytes
Database mounted.
Database opened.
3) Connect to the primary database and create the standby control file:
SQL> alter database create standby control file as
'/export/home/oracle/temp/oracle/data/backup/standby.ctl';
Database altered.
4) Copy files to the Standby host
Copy the backup data files, standby control file, all available archived redo logs, and online redo logs from the primary site to the standby site. Copying of the online redo logs is necessary to facilitate switchover. If the standby is on a separate site with the same directory structure as the primary database then you can use the same path names for the standby files as the primary files. In this way, you do not have to rename the primary data files in the standby control file. If the standby is on the same site as the primary database, or the standby database is on a separate site with a different directory structure the you must rename the primary data files in the standby control file after copying them to the standby site. This can be done using the db_file_name_convert and log_file_name_convert parameters or by manually using the alert database statements.
5) Set the initialization parameters for the primary database
It is suggested that you maintain two init.ora files on both the primary and the standby databases. This allows you to facilitate role reversal during switchover operations more easily.
For primary database ========
1. initTEST.ora
2. switch_to_stdby_initTEST
For Standby database =======
1. initTEST_s1.ora
2. switch_to_primary_initTEST
On primary initTEST.ora file add the following lines:
log_archive_dest_1='LOCATION=/export/home/oracle/temp/oracle/arch’
log_archive_dest_2='SERVICE=TEST_s1 reopen=60'
log_archive_dest_state_1=enable
log_archive_dest_state_2=enable
log_archive_format=%t_%s.dbf
log_archive_start=true
remote_archive_enable=true
Create the standby initialization parameter file and set the parameters for the standby database. Depending on your configuration, you may need to set filename conversion parameters.
Standby init.ora on Primary host:
log_archive_dest_1='LOCATION=/export/home/oracle/temp/oracle/arch'
log_archive_dest_state_1=enable
log_archive_format=%t_%s.dbf
log_archive_start=true
standby_archive_dest=/export/home/oracle/temp/oracle/arch
standby_file_management=auto
fal_server=TEST_s1
fal_client=TEST
remote_arhive_enable=true
NOTE: In the above example, db_file_name_convert and log_file_name_convert are not needed as the directory structure on the two hosts are the same. If the directory structure is not the same then setting of these parameters is recommended.
6) Configure networking components
On the Primary host create a net service name that the Primary database can use to connect to the Standby database. On the primary host creates a net service name that Standby, when running on the Primary host, can use to connect to the Primary, when it is running on the Standby host. Example from
Primary’s host tnsnames.ora:
TEST =
(DESCRIPTION =
(ADDRESS= (PROTOCOL= TCP) (Host= 172.20.69.83) (Port= 1523))
(CONNECT_DATA = (SID= TEST))
)
TEST_s1 =
(DESCRIPTION =
(ADDRESS= (PROTOCOL= TCP) (Host= 172.20.89.7) (Port= 1530))
(CONNECT_DATA = (SID= TEST))
)
The above two net service names must exist in the Standby hosts tnsnames.ora also. You must also configure a listener on the standby database. If you plan to manage this standby database using the Data Guard broker, you must configure the listener to use the TCP/IP protocol and statically register the standby database service using its SID.
7) Start up and mount the stand by database
oracle@hasunclu2:/export/home/oracle/temp/oracle> sqlplus "/ as sysdba"
SQL*Plus: Release 9.0.1.0.0 - Production on Thu Mar 14 18:00:57 2002 (c) Copyright 2001 Oracle Corporation. All rights reserved.
Connected to an idle instance.
SQL> startup nomount pfile=?/dbs/initTEST_s1.ora
ORACLE instance started.
Total System Global Area 80512156 bytes
Fixed Size 279708 bytes
Variable Size 71303168 bytes
Database Buffers 8388608 bytes
Redo Buffers 540672 bytes
SQL> alter database mount standby database;
Database altered.
SQL>
8) Create standby redo log files, if necessary
Standby redo logs are necessary for the higher protection levels such as Guaranteed, Instant, and Rapid. In these protection modes LGWR from the Primary host writes transactions directly to the standby redo logs. This enables no data loss solutions and reduces the amount of data loss in the event of failure. Standby redo logs are not necessary if you are using the delayed protection mode.
If you configure standby redo on the standby then you should also configure standby redo logs on the primary database. Even though the standby redo logs are not used when the database is running in the primary role, configuring the standby redo logs on the primary database is recommended in preparation for an eventual switchover operation.
Standby redo logs must be archived before the data can be applied to the standby database. The standby archival operation occurs automatically, even if the standby database is not in ARCHIVELOG mode. However, the archive process must be started on the standby database. Note that the use of the archiver process (ARCn) is a requirement for selection of a standby redo log.
You must have the same number of standby redo logs on the standby as you have online redo logs on production. They must also be exactly the same size.
The following syntax is used to create standby redo logs:
SQL> alter database add standby log file
'/export/home/oracle/temp/oracle/data/srl_1.dbf' size 20m;
Database altered.
SQL> alter database add standby log file
2 '/export/home/oracle/temp/oracle/data/srl_2.dbf' size 20m;
Database altered.
SQL> alter database add standby log file
2 ‘/export/home/oracle/temp/oracle/data/srl_3.dbf' size 20m;
Database altered.
SQL>
9) Copy database files
Manually change the names of the primary data files and redo logs in the standby control file for all files not automatically renamed using DB_FILE_NAME_CONVERT and LOG_FILE_NAME_CONVERT as noted in step 5.Datafile names can be changed on the standby at a mounted state with the following syntax:
SQL> alter database rename file
'/export/home/oracle/temp/oracle/data/sys.dbf'
to
'/export/home/oracle/temp/oracle/data2/sys.dbf';
10) Restart the listeners
On the primary database, and start the listener on the standby database so that changes made to the listener.ora can be implemented.
11) Activate parameter changes
Manually enable initialization parameter changes on the primary database so that it can initiate archiving to the standby site.
At runtime, the LOG_ARCHIVE_DEST_n initialization parameter can be changed using ALTER SYSTEM and ALTER SESSION statements. Activate the changes made to these parameters by either bouncing the instance or activating via alter system.
For example:
SQL> alter system set log_archive_dest_2='SERVICE=TEST_s1 reopen=60';
System altered.
12) Verify Auto Archive
On the Primary database switch a log and verify that it has been shipped properly using the v$archive_dest view.
SQL> alter system switch logfile;
System altered.
SQL> select status, error from v$archive_dest where dest_id=2;
STATUS ERROR
--------- ------------------------------------------------------
VALID
SQL>
13) Put Standby database in managed standby database
SQL> recover managed standby database disconnect;
Media recovery complete.
SQL> exit
14)Apply redo logs in the standby database
Remember archived logs will be transferred to stand by database. But we need to apply the archived logs to standby database. We can apply these archived logs either thru SQL or data guard command line tool (DGMGRL)
Let us see how we can apply thru SQL.
Go to standby database environment:
SQL> startup nomount pfile=initTEST_s1.ora
SQL> alter database mount standby database;
SQL> recover managed standby database disconnect;
Warning!!!After executing the above statement you will get the sql prompt. But that does not mean the recovery is complete. This statement will kick off “Disaster Recovery Service”.
SQL> recover managed standby database cancel;
The above statement will complete media recovery. Now all archive redo logs applied to standby database.
15) Switchover databases
In real time environment, if primary database is crashed or unavailable for some reason you need to make standby database as primary database.
• Switchover Standby to Primary
In order to do switchover standby have to be in mount state.
SQL> alter database commit to switch over to primary;
Sometimes, this command will ask to do media recovery on stand by instance. Apply logs as mentioned above and rerun the command.
SQL> shutdown immediate;
SQL> startup pfile=switch_to_primary_initTEST.ora
• Switchover Primary to Standby
SQL>alter database commit to switch over to standby;
SQL> shutdown immediate;
SQL> startup pfile= switch_to_stdby_initTEST.ora
How to Create Logical Standby Database
Now, let us talk about how we can create one logical standby database and administer logical standby database.
Before we create logical database perform the following checks to make sure the primary database qualify to have logical standby database.
• Determine whether primary database contains data types like LONG, NCLOB, LONG RAW, BFILE those are not supported by standby database.
• Ensure that the tables in primary database can be uniquely identified.
• Ensure that the primary database is in ARCHIVELOG mode and that archiving is enabled.
• Ensure supplemental logging is enabled on the primary database. To see whether supplemental logging is enabled, start a SQL session and query the V$DATABASE fixed view. For example, enter:
SQL> SELECT SUPPLEMENTAL_LOG_DATA_PK, SUPPLEMENTAL_LOG_DATA_UI
FROM V$DATABASE;
SUP SUP
--- ---
YES YES
If supplemental logging is not enabled, execute the following statements:
SQL> ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (PRIMARY KEY, UNIQUE INDEX) COLUMNS;
SQL> ALTER SYSTEM SWITCH LOGFILE;
• Ensure LOG_PARALLELISM init.ora parameter is set to 1 (default value).If you plan to be performing switchover operations with the logical standby then you must create an alternate tablespace in the primary database for logical standby system tables. Use the DBMS_LOGMNR_D.SET_TABLESPACE procedure to move the tables into the new tablespace. For example:
SQL> EXECUTE LOGMNR_D.SET_TABLESPACE
'logical_tblsp');
Steps to create Logical Standby Database
1. On primary database, perform cold backup.
2. Bring the primary database to mount state to create backup of control file.
3. Open the primary database and build the log miner dictionary.
SQL> ALTER system enable restricted session;
SQL> ALTER DATABASE OPEN;
SQL> EXECUTE DBMS_LOGSTDBY.BUILD;
4. Archive the current online redo log and disable the restricted session.
5. Identify the archived redo log that contains the log miner dictionary
SQL> SELECT NAME FROM V$ARCHIVED_LOG WHERE DICTIONARY_BEGIN='YES'
AND STANDBY_DEST='NO';
6. . Copy all these files with init parameter file to the stand by database.
7. On standby system, modify the copied primary init file to support the logical standby feature. Some parameters affected are control_files,standby_archive_dest,parallel_max_servers,instance_name.
8. Start and mount the standby database in exclusive mode.
9. Turn on the database guard.
ALTER DATABASE GUARD ALL;
10. Open the logical standby followed by a shutdown immediate or normal.
SQL> ALTER DATABASE OPEN RESETLOGS;
SQL> SHUTDOWN IMMEDIATE;
11. Open the logical standby database in exclusive mode.
12. Create temporary table space for the standby database.
13. On logical standby database, register the archived log identified in step 5 and run the following command.
SQL> ALTER DATABASE REGISTER LOGICAL LOGFILE
'/u01/oradata/stby/arch/arc1_28.arc';
14. Run the following ALTER DATABASE statement and include the INITIAL keyword to begin SQL apply operations for the first time on the logical standby.
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY INITIAL;
15. Configure listener on the standby database.
16. Once listeners running on both primary and standby databases run the following command.
ALTER SYSTEM RESGITER;
17. Create tns names entry for primary database in standby host. Similarly, create tns names entry for standby database in primary host.
18. Enable archiving in the logical standby database.
19. Start archive the current online redo log file. Verify that the remote archiving succeeded by running the following select statement.
SQL> SELECT STATUS, ERROR FROM V$ARCHIVE_DEST;
20. Verifying archived redo logs are being applied. To verify that the archived redo logs are being applied, query the V$LOGSTDBY view. This view provides information about the processes that are reading redo log information and applying it to the logical standby databases. You can also query the DBA_LOGSTDBY_PROGRESS view to find out the progress of SQL apply operations. The V$LOGSTDBY_STATS view shows the state of the coordinator process and information about the SQL transactions that have been applied to the logical standby database.
Logical or Physical, What is your Choice?
You ask you DBA to implement “stand by “database for your production database. Guess what? You will get “physical standby “database implemented for your production database. Because implementing physical standby database would be first choice for many DBAs as most of us would not realize the benefits we get from having logical standby database.
Let us take close look at the major bottleneck with physical stand by database.
We need to keep the physical standby database in “recovery mode” in order to apply the received archive logs from the primary database. We can open “physical stand by database to “read only” and make it available to the applications users (Only select is allowed during this period).Once the database is opened in “Read only” mode then we can not apply redo logs received from primary database.
We do not see such issues with logical standby database. We can open up the database in normal mode and make it available to the users. At the same time, we can apply archived logs received from primary database.
Real World Scenario
One of my clients was facing critical performance issue with their primary database. The primary database needed to support pretty large user community for the OLTP system and pretty large “Reporting Group”. The database could not cope up with these two large user groups. So I have configured “logical stand by” database for the primary database and I have opened up the database available to the reporting users group. Now the database load is kind of distributed between primary and standby database.
Conclusion
I will hazard a guess that you and many users now have a newfound respect for standby databases. In future, if you need to create standby databases ask yourself the following questions.
• Do I need just one failover database? Then you can choose physical standby database.
• Do I need failover database? Also I need to see whether I can make use of this failover database rather than sitting idle on the server. Then choose logical standby database.
table fragmentation
Table Fragmentation
by Mohammad taj
When rows are not stored contiguously, or if rows are split onto more than one block, performance decreases because these rows require additional block accesses.
Note that table fragmentation is different from file fragmentation. When a lot of DML operations are applied on a table, the table will become fragmented because DML does not release free space from the table below the HWM.
HWM is an indicator of USED BLOCKS in the database. Blocks below the high water mark (used blocks) have at least once contained data. This data might have been deleted. Since Oracle knows that blocks beyond the high water mark don't have data, it only reads blocks up to the high water mark when doing a full table scan.
DDL statement always resets the HWM.
How to find table fragmentation?
SQL> select count(*) from big1;
1000000 rows selected.
SQL> delete from big1 where rownum <= 300000;
300000 rows deleted.
SQL> commit;
Commit complete.
SQL> update big1 set object_id = 0 where rownum <=350000;
342226 rows updated.
SQL> commit;
Commit complete.
SQL> exec dbms_stats.gather_table_stats('SCOTT','BIG1');
PL/SQL procedure successfully completed.
Table size (with fragmentation)
SQL> select table_name,round((blocks*8),2)||'kb' "size"
2 from user_tables
3 where table_name = 'BIG1';
TABLE_NAME size
------------------------------ ------------------------------------------
BIG1 72952kb
Actual data in table:
SQL> select table_name,round((num_rows*avg_row_len/1024),2)||'kb' "size"
2 from user_tables
3 where table_name = 'BIG1';
TABLE_NAME size
------------------------------ ------------------------------------------
BIG1 30604.2kb
Note = 72952 - 30604 = 42348 Kb is wasted space in table
The difference between two values is 60% and Pctfree 10% (default) - so, the table has 50% extra space which is wasted because there is no data.
How to reset HWM / remove fragemenation?
For that we need to reorganize the fragmented table.
We have four options to reorganize fragmented tables:
1. alter table ... move + rebuild indexes
2. export / truncate / import
3. create table as select ( CTAS)
4. dbms_redefinition
Option: 1 "alter table ... move + rebuild indexes"
SQL> alter table BIG1 move;
Table altered.
SQL> select status,index_name from user_indexes
2 where table_name = 'BIG1';
STATUS INDEX_NAME
-------- ------------------------------
UNUSABLE BIGIDX
SQL> alter index bigidx rebuild;
Index altered.
SQL> select status,index_name from user_indexes
2 where table_name = 'BIG1';
STATUS INDEX_NAME
-------- ------------------------------
VALID BIGIDX
SQL> exec dbms_stats.gather_table_stats('SCOTT','BIG1');
PL/SQL procedure successfully completed.
SQL> select table_name,round((blocks*8),2)||'kb' "size"
2 from user_tables
3 where table_name = 'BIG1';
TABLE_NAME size
------------------------------ ------------------------------------------
BIG1 38224kb
SQL> select table_name,round((num_rows*avg_row_len/1024),2)||'kb' "size"
2 from user_tables
3 where table_name = 'BIG1';
TABLE_NAME size
------------------------------ ------------------------------------------
BIG1 30727.37kb
Option: 2 “Create table as select”
SQL> create table big2 as select * from big1;
Table created.
SQL> drop table big1 purge;
Table dropped.
SQL> rename big2 to big1;
Table renamed.
SQL> exec dbms_stats.gather_table_stats('SCOTT','BIG1');
PL/SQL procedure successfully completed.
SQL> select table_name,round((blocks*8),2)||'kb' "size"
2 from user_tables
3 where table_name = 'BIG1';
TABLE_NAME size
------------------------------ ------------------------------------------
BIG1 85536kb
SQL> select table_name,round((num_rows*avg_row_len/1024),2)||'kb' "size"
2 from user_tables
3 where table_name = 'BIG1';
TABLE_NAME size
------------------------------ ------------------------------------------
BIG1 68986.97kb
SQL> select status from user_indexes
2 where table_name = 'BIG1';
no rows selected
SQL> --Note we need to create all indexes.
Option: 3 "export / truncate / import"
SQL> select table_name, round((blocks*8),2)||'kb' "size"
2 from user_tables
3 where table_name = 'BIG1';
TABLE_NAME size
------------------------------ ------------------------------------------
BIG1 85536kb
SQL> select table_name, round((num_rows*avg_row_len/1024),2)||'kb' "size"
2 from user_tables
3 where table_name = 'BIG1';
TABLE_NAME size
------------------------------ ------------------------------------------
BIG1 42535.54kb
SQL> select status from user_indexes where table_name = 'BIG1';
STATUS
--------
VALID
SQL> exit
Disconnected from Oracle Database 10g Enterprise Edition Release 10.1.0.5.0 - Pr
oduction
With the Partitioning, OLAP and Data Mining options
C:\>exp scott/tiger@Orcl file=c:\big1.dmp tables=big1
Export: Release 10.1.0.5.0 - Production on Sat Jul 28 16:30:44 2007
Copyright (c) 1982, 2005, Oracle. All rights reserved.
Connected to: Oracle Database 10g Enterprise Edition Release 10.1.0.5.0 - Produc
tion
With the Partitioning, OLAP and Data Mining options
Export done in WE8MSWIN1252 character set and AL16UTF16 NCHAR character set
About to export specified tables via Conventional Path ...
. . exporting table BIG1 468904 rows exported
Export terminated successfully without warnings.
C:\>sqlplus scott/tiger@orcl
SQL*Plus: Release 10.1.0.5.0 - Production on Sat Jul 28 16:31:12 2007
Copyright (c) 1982, 2005, Oracle. All rights reserved.
Connected to:
Oracle Database 10g Enterprise Edition Release 10.1.0.5.0 - Production
With the Partitioning, OLAP and Data Mining options
SQL> truncate table big1;
Table truncated.
SQL> exit
Disconnected from Oracle Database 10g Enterprise Edition Release 10.1.0.5.0 - Pr
oduction
With the Partitioning, OLAP and Data Mining options
C:\>imp scott/tiger@Orcl file=c:\big1.dmp ignore=y
Import: Release 10.1.0.5.0 - Production on Sat Jul 28 16:31:54 2007
Copyright (c) 1982, 2005, Oracle. All rights reserved.
Connected to: Oracle Database 10g Enterprise Edition Release 10.1.0.5.0 - Produc
tion
With the Partitioning, OLAP and Data Mining options
Export file created by EXPORT:V10.01.00 via conventional path
import done in WE8MSWIN1252 character set and AL16UTF16 NCHAR character set
. importing SCOTT's objects into SCOTT
. . importing table "BIG1" 468904 rows imported
Import terminated successfully without warnings.
C:\>sqlplus scott/tiger@orcl
SQL*Plus: Release 10.1.0.5.0 - Production on Sat Jul 28 16:32:21 2007
Copyright (c) 1982, 2005, Oracle. All rights reserved.
Connected to:
Oracle Database 10g Enterprise Edition Release 10.1.0.5.0 - Production
With the Partitioning, OLAP and Data Mining options
SQL> select table_name, round((blocks*8),2)||'kb' "size"
2 from user_tables
3 where table_name = 'BIG1';
TABLE_NAME size
------------------------------ ------------------------------------------
BIG1 85536kb
SQL> select table_name, round((num_rows*avg_row_len/1024),2)||'kb' "size"
2 from user_tables
3 where table_name = 'BIG1';
TABLE_NAME size
------------------------------ ------------------------------------------
BIG1 42535.54kb
SQL> exec dbms_stats.gather_table_stats('SCOTT','BIG1');
PL/SQL procedure successfully completed.
SQL> select table_name, round((blocks*8),2)||'kb' "size"
2 from user_tables
3 where table_name = 'BIG1';
TABLE_NAME size
------------------------------ ------------------------------------------
BIG1 51840kb
SQL> select table_name, round((num_rows*avg_row_len/1024),2)||'kb' "size"
2 from user_tables
3 where table_name = 'BIG1';
TABLE_NAME size
------------------------------ ------------------------------------------
BIG1 42542.27kb
SQL> select status from user_indexes where table_name = 'BIG1';
STATUS
--------
VALID
SQL> exec dbms_redefinition.can_redef_table('SCOTT','BIG1',-
> dbms_redefinition.cons_use_pk);
PL/SQL procedure successfully completed.
Option: 4 "dbms_redefinition"
SQL> create table TABLE1 (
2 no number,
3 name varchar2(20) default 'NONE',
4 ddate date default SYSDATE);
Table created.
SQL> alter table table1 add constraint pk_no primary key(no);
Table altered.
SQL> begin
2 for x in 1..100000 loop
3 insert into table1 ( no , name, ddate)
4 values ( x , default, default);
5 end loop;
6 end;
7 /
PL/SQL procedure successfully completed.
SQL> create or replace trigger tri_table1
2 after insert on table1
3 begin
4 null;
5 end;
6 /
Trigger created.
SQL> select count(*) from table1;
COUNT(*)
----------
100000
SQL> delete table1 where rownum <= 50000;
50000 rows deleted.
SQL> commit;
Commit complete.
SQL> exec dbms_stats.gather_table_stats('SCOTT','TABLE1');
PL/SQL procedure successfully completed.
SQL> select table_name, round((blocks*8),2)||'kb' "size"
2 from user_tables
3 where table_name = 'TABLE1';
TABLE_NAME size
------------------------------ ------------------------------------------
TABLE1 2960kb
SQL> select table_name, round((num_rows*avg_row_len/1024),2)||'kb' "size"
2 from user_tables
3 where table_name = 'TABLE1';
TABLE_NAME size
------------------------------ ------------------------------------------
TABLE1 822.69kb
SQL> --Minimum Privs required "DBA" role or "SELECT" on dbms_redefinition pkg
SQL> --First check table is condidate for redefinition.
SQL>
SQL> exec sys.dbms_redefinition.can_redef_table('SCOTT',-
> 'TABLE1',-
> sys.dbms_redefinition.cons_use_pk);
PL/SQL procedure successfully completed.
SQL> --After verifying that the table can be redefined online, you manually crea
te an empty interim table (in the same schema as the table to be redefined)
SQL>
SQL> create table TABLE2 as select * from table1 WHERE 1 = 2;
Table created.
SQL> exec sys.dbms_redefinition.start_redef_table ( 'SCOTT',-
> 'TABLE1',-
> 'TABLE2');
PL/SQL procedure successfully completed.
SQL> --This procedure keeps the interim table synchronized with the original tab
le.
SQL>
SQL> exec sys.dbms_redefinition.sync_interim_table ('SCOTT',-
> 'TABLE1',-
> 'TABLE2');
PL/SQL procedure successfully completed.
SQL> --Create PRIMARY KEY on interim table(TABLE2)
SQL> alter table TABLE2
2 add constraint pk_no1 primary key (no);
Table altered.
SQL> create trigger tri_table2
2 after insert on table2
3 begin
4 null;
5 end;
6 /
Trigger created.
SQL> --Disable foreign key on original table if exists before finish this proces
s.
SQL>
SQL> exec sys.dbms_redefinition.finish_redef_table ( 'SCOTT',-
> 'TABLE1',-
> 'TABLE2');
PL/SQL procedure successfully completed.
SQL> exec dbms_stats.gather_table_stats('SCOTT','TABLE1');
PL/SQL procedure successfully completed.
SQL> select table_name, round((blocks*8),2)||'kb' "size"
2 from user_tables
3 where table_name = 'TABLE1';
TABLE_NAME size
------------------------------ ------------------------------------------
TABLE1 1376kb
SQL> select table_name, round((num_rows*avg_row_len/1024),2)||'kb' "size"
2 from user_tables
3 where table_name = 'TABLE1';
TABLE_NAME size
------------------------------ ------------------------------------------
TABLE1 841.4kb
SQL> select status,constraint_name
2 from user_constraints
3 where table_name = 'TABLE1';
STATUS CONSTRAINT_NAME
-------- ------------------------------
ENABLED PK_NO1
SQL> select status ,trigger_name
2 from user_triggers
3 where table_name = 'TABLE1';
STATUS TRIGGER_NAME
-------- ------------------------------
ENABLED TRI_TABLE2
SQL> drop table TABLE2 PURGE;
Table dropped.
for more information pls visit the following sites
http://dbataj.blogspot.com/2007/07/table-fragmentation.html
http://www.orafaq.com/node/1936
by Mohammad taj
When rows are not stored contiguously, or if rows are split onto more than one block, performance decreases because these rows require additional block accesses.
Note that table fragmentation is different from file fragmentation. When a lot of DML operations are applied on a table, the table will become fragmented because DML does not release free space from the table below the HWM.
HWM is an indicator of USED BLOCKS in the database. Blocks below the high water mark (used blocks) have at least once contained data. This data might have been deleted. Since Oracle knows that blocks beyond the high water mark don't have data, it only reads blocks up to the high water mark when doing a full table scan.
DDL statement always resets the HWM.
How to find table fragmentation?
SQL> select count(*) from big1;
1000000 rows selected.
SQL> delete from big1 where rownum <= 300000;
300000 rows deleted.
SQL> commit;
Commit complete.
SQL> update big1 set object_id = 0 where rownum <=350000;
342226 rows updated.
SQL> commit;
Commit complete.
SQL> exec dbms_stats.gather_table_stats('SCOTT','BIG1');
PL/SQL procedure successfully completed.
Table size (with fragmentation)
SQL> select table_name,round((blocks*8),2)||'kb' "size"
2 from user_tables
3 where table_name = 'BIG1';
TABLE_NAME size
------------------------------ ------------------------------------------
BIG1 72952kb
Actual data in table:
SQL> select table_name,round((num_rows*avg_row_len/1024),2)||'kb' "size"
2 from user_tables
3 where table_name = 'BIG1';
TABLE_NAME size
------------------------------ ------------------------------------------
BIG1 30604.2kb
Note = 72952 - 30604 = 42348 Kb is wasted space in table
The difference between two values is 60% and Pctfree 10% (default) - so, the table has 50% extra space which is wasted because there is no data.
How to reset HWM / remove fragemenation?
For that we need to reorganize the fragmented table.
We have four options to reorganize fragmented tables:
1. alter table ... move + rebuild indexes
2. export / truncate / import
3. create table as select ( CTAS)
4. dbms_redefinition
Option: 1 "alter table ... move + rebuild indexes"
SQL> alter table BIG1 move;
Table altered.
SQL> select status,index_name from user_indexes
2 where table_name = 'BIG1';
STATUS INDEX_NAME
-------- ------------------------------
UNUSABLE BIGIDX
SQL> alter index bigidx rebuild;
Index altered.
SQL> select status,index_name from user_indexes
2 where table_name = 'BIG1';
STATUS INDEX_NAME
-------- ------------------------------
VALID BIGIDX
SQL> exec dbms_stats.gather_table_stats('SCOTT','BIG1');
PL/SQL procedure successfully completed.
SQL> select table_name,round((blocks*8),2)||'kb' "size"
2 from user_tables
3 where table_name = 'BIG1';
TABLE_NAME size
------------------------------ ------------------------------------------
BIG1 38224kb
SQL> select table_name,round((num_rows*avg_row_len/1024),2)||'kb' "size"
2 from user_tables
3 where table_name = 'BIG1';
TABLE_NAME size
------------------------------ ------------------------------------------
BIG1 30727.37kb
Option: 2 “Create table as select”
SQL> create table big2 as select * from big1;
Table created.
SQL> drop table big1 purge;
Table dropped.
SQL> rename big2 to big1;
Table renamed.
SQL> exec dbms_stats.gather_table_stats('SCOTT','BIG1');
PL/SQL procedure successfully completed.
SQL> select table_name,round((blocks*8),2)||'kb' "size"
2 from user_tables
3 where table_name = 'BIG1';
TABLE_NAME size
------------------------------ ------------------------------------------
BIG1 85536kb
SQL> select table_name,round((num_rows*avg_row_len/1024),2)||'kb' "size"
2 from user_tables
3 where table_name = 'BIG1';
TABLE_NAME size
------------------------------ ------------------------------------------
BIG1 68986.97kb
SQL> select status from user_indexes
2 where table_name = 'BIG1';
no rows selected
SQL> --Note we need to create all indexes.
Option: 3 "export / truncate / import"
SQL> select table_name, round((blocks*8),2)||'kb' "size"
2 from user_tables
3 where table_name = 'BIG1';
TABLE_NAME size
------------------------------ ------------------------------------------
BIG1 85536kb
SQL> select table_name, round((num_rows*avg_row_len/1024),2)||'kb' "size"
2 from user_tables
3 where table_name = 'BIG1';
TABLE_NAME size
------------------------------ ------------------------------------------
BIG1 42535.54kb
SQL> select status from user_indexes where table_name = 'BIG1';
STATUS
--------
VALID
SQL> exit
Disconnected from Oracle Database 10g Enterprise Edition Release 10.1.0.5.0 - Pr
oduction
With the Partitioning, OLAP and Data Mining options
C:\>exp scott/tiger@Orcl file=c:\big1.dmp tables=big1
Export: Release 10.1.0.5.0 - Production on Sat Jul 28 16:30:44 2007
Copyright (c) 1982, 2005, Oracle. All rights reserved.
Connected to: Oracle Database 10g Enterprise Edition Release 10.1.0.5.0 - Produc
tion
With the Partitioning, OLAP and Data Mining options
Export done in WE8MSWIN1252 character set and AL16UTF16 NCHAR character set
About to export specified tables via Conventional Path ...
. . exporting table BIG1 468904 rows exported
Export terminated successfully without warnings.
C:\>sqlplus scott/tiger@orcl
SQL*Plus: Release 10.1.0.5.0 - Production on Sat Jul 28 16:31:12 2007
Copyright (c) 1982, 2005, Oracle. All rights reserved.
Connected to:
Oracle Database 10g Enterprise Edition Release 10.1.0.5.0 - Production
With the Partitioning, OLAP and Data Mining options
SQL> truncate table big1;
Table truncated.
SQL> exit
Disconnected from Oracle Database 10g Enterprise Edition Release 10.1.0.5.0 - Pr
oduction
With the Partitioning, OLAP and Data Mining options
C:\>imp scott/tiger@Orcl file=c:\big1.dmp ignore=y
Import: Release 10.1.0.5.0 - Production on Sat Jul 28 16:31:54 2007
Copyright (c) 1982, 2005, Oracle. All rights reserved.
Connected to: Oracle Database 10g Enterprise Edition Release 10.1.0.5.0 - Produc
tion
With the Partitioning, OLAP and Data Mining options
Export file created by EXPORT:V10.01.00 via conventional path
import done in WE8MSWIN1252 character set and AL16UTF16 NCHAR character set
. importing SCOTT's objects into SCOTT
. . importing table "BIG1" 468904 rows imported
Import terminated successfully without warnings.
C:\>sqlplus scott/tiger@orcl
SQL*Plus: Release 10.1.0.5.0 - Production on Sat Jul 28 16:32:21 2007
Copyright (c) 1982, 2005, Oracle. All rights reserved.
Connected to:
Oracle Database 10g Enterprise Edition Release 10.1.0.5.0 - Production
With the Partitioning, OLAP and Data Mining options
SQL> select table_name, round((blocks*8),2)||'kb' "size"
2 from user_tables
3 where table_name = 'BIG1';
TABLE_NAME size
------------------------------ ------------------------------------------
BIG1 85536kb
SQL> select table_name, round((num_rows*avg_row_len/1024),2)||'kb' "size"
2 from user_tables
3 where table_name = 'BIG1';
TABLE_NAME size
------------------------------ ------------------------------------------
BIG1 42535.54kb
SQL> exec dbms_stats.gather_table_stats('SCOTT','BIG1');
PL/SQL procedure successfully completed.
SQL> select table_name, round((blocks*8),2)||'kb' "size"
2 from user_tables
3 where table_name = 'BIG1';
TABLE_NAME size
------------------------------ ------------------------------------------
BIG1 51840kb
SQL> select table_name, round((num_rows*avg_row_len/1024),2)||'kb' "size"
2 from user_tables
3 where table_name = 'BIG1';
TABLE_NAME size
------------------------------ ------------------------------------------
BIG1 42542.27kb
SQL> select status from user_indexes where table_name = 'BIG1';
STATUS
--------
VALID
SQL> exec dbms_redefinition.can_redef_table('SCOTT','BIG1',-
> dbms_redefinition.cons_use_pk);
PL/SQL procedure successfully completed.
Option: 4 "dbms_redefinition"
SQL> create table TABLE1 (
2 no number,
3 name varchar2(20) default 'NONE',
4 ddate date default SYSDATE);
Table created.
SQL> alter table table1 add constraint pk_no primary key(no);
Table altered.
SQL> begin
2 for x in 1..100000 loop
3 insert into table1 ( no , name, ddate)
4 values ( x , default, default);
5 end loop;
6 end;
7 /
PL/SQL procedure successfully completed.
SQL> create or replace trigger tri_table1
2 after insert on table1
3 begin
4 null;
5 end;
6 /
Trigger created.
SQL> select count(*) from table1;
COUNT(*)
----------
100000
SQL> delete table1 where rownum <= 50000;
50000 rows deleted.
SQL> commit;
Commit complete.
SQL> exec dbms_stats.gather_table_stats('SCOTT','TABLE1');
PL/SQL procedure successfully completed.
SQL> select table_name, round((blocks*8),2)||'kb' "size"
2 from user_tables
3 where table_name = 'TABLE1';
TABLE_NAME size
------------------------------ ------------------------------------------
TABLE1 2960kb
SQL> select table_name, round((num_rows*avg_row_len/1024),2)||'kb' "size"
2 from user_tables
3 where table_name = 'TABLE1';
TABLE_NAME size
------------------------------ ------------------------------------------
TABLE1 822.69kb
SQL> --Minimum Privs required "DBA" role or "SELECT" on dbms_redefinition pkg
SQL> --First check table is condidate for redefinition.
SQL>
SQL> exec sys.dbms_redefinition.can_redef_table('SCOTT',-
> 'TABLE1',-
> sys.dbms_redefinition.cons_use_pk);
PL/SQL procedure successfully completed.
SQL> --After verifying that the table can be redefined online, you manually crea
te an empty interim table (in the same schema as the table to be redefined)
SQL>
SQL> create table TABLE2 as select * from table1 WHERE 1 = 2;
Table created.
SQL> exec sys.dbms_redefinition.start_redef_table ( 'SCOTT',-
> 'TABLE1',-
> 'TABLE2');
PL/SQL procedure successfully completed.
SQL> --This procedure keeps the interim table synchronized with the original tab
le.
SQL>
SQL> exec sys.dbms_redefinition.sync_interim_table ('SCOTT',-
> 'TABLE1',-
> 'TABLE2');
PL/SQL procedure successfully completed.
SQL> --Create PRIMARY KEY on interim table(TABLE2)
SQL> alter table TABLE2
2 add constraint pk_no1 primary key (no);
Table altered.
SQL> create trigger tri_table2
2 after insert on table2
3 begin
4 null;
5 end;
6 /
Trigger created.
SQL> --Disable foreign key on original table if exists before finish this proces
s.
SQL>
SQL> exec sys.dbms_redefinition.finish_redef_table ( 'SCOTT',-
> 'TABLE1',-
> 'TABLE2');
PL/SQL procedure successfully completed.
SQL> exec dbms_stats.gather_table_stats('SCOTT','TABLE1');
PL/SQL procedure successfully completed.
SQL> select table_name, round((blocks*8),2)||'kb' "size"
2 from user_tables
3 where table_name = 'TABLE1';
TABLE_NAME size
------------------------------ ------------------------------------------
TABLE1 1376kb
SQL> select table_name, round((num_rows*avg_row_len/1024),2)||'kb' "size"
2 from user_tables
3 where table_name = 'TABLE1';
TABLE_NAME size
------------------------------ ------------------------------------------
TABLE1 841.4kb
SQL> select status,constraint_name
2 from user_constraints
3 where table_name = 'TABLE1';
STATUS CONSTRAINT_NAME
-------- ------------------------------
ENABLED PK_NO1
SQL> select status ,trigger_name
2 from user_triggers
3 where table_name = 'TABLE1';
STATUS TRIGGER_NAME
-------- ------------------------------
ENABLED TRI_TABLE2
SQL> drop table TABLE2 PURGE;
Table dropped.
for more information pls visit the following sites
http://dbataj.blogspot.com/2007/07/table-fragmentation.html
http://www.orafaq.com/node/1936
Subscribe to:
Posts (Atom)

